Everyone says they have a REST API. Twitter does, Facebook does, as does Twilio and Gowalla and even Google. However, by the actual, original definition, none of them are truly RESTful. But that’s OK, because your API shouldn’t be either.
Years ago Michael Bleigh wrote a brilliant article connected with REST API. It should not be forgotten, and that is why here it is at your disposal.
What is RESTful API?
The misconception lies in the fact that, as tends to happen, the popular definition of a technical term has come to mean something entirely different from its original meaning. To most people, being RESTful means a few things:
- Well-defined URIs that “represent” some kind of resource, such as “/posts” on a blog representing the blog posts.
- HTTP methods being used as verbs to perform actions on that resource (i.e. GET for read operations and POST for write operations).
- The ability to access multiple format representations of the same data (i.e. both a JSON and an XML representation of a blog post).
There are some other parts of the common vocabulary of REST (for example, for some developers being RESTful would also imply a URI hierarchy such that /posts/{uniqueid}would be seen to be a member of the /posts collection), but these are what most people think of when they hear “RESTful web service.” So how is this different from the “actual” definition of REST?
Diverging From Canon
By the common definition of REST, a service defines a set of resources and actions that can be accessed via URI endpoints. However, the “true” definition of REST demands that resources be self-describing, providing all of the control context in-band of the provided representation. No out-of-band knowledge should, therefore, be required beyond understanding a media type that the resource can provide. From there, it should be possible to follow relations provided in “hypertext” context of the representation to “transfer state”, follow relations, or perform any necessary actions.
Another common divergence comes through the practice of using HTTP POST (or PUT) bodies with key-value pairs to create and update documents. In a canonically RESTful service clients should be posting an actual representation of the document in an accepted media type that is then parsed and translated by the service provider to create or update the resource.
Still more divergence comes in the common practice of denoting collections and elements. A truly RESTful web service has no concept of a “collection” of resources. There are only resources. As such, the proper way to implement a collection would be to define a separate resource that represents a collection of other resources.
Is Anything Truly RESTful?
Pretty much everyone who claims to have a REST API, in fact, does not. The closest I’ve found is the Sun Cloud API which actually defines a number of custom media types for resources and is discoverable based on a single known end-point. Everyone else, thanks for playing.
There is, however, one public and extremely widely used system that is entirely RESTful. It’s called the world wide web. Yes, as you’re browsing the internet you’re engaging in a REST service by the true definition of the name. Does your browser (the client) know whether it’s displaying a banking website or a casual game? Nope, it just utilizes standard media types (HTML, CSS, Javascript) to compose and represent the data. You don’t have to know the specific URL you’re looking for on a website so long as you know the “starting place” (usually the domain name) and can navigate there.
So REST by its original definition is far from useless. In fact, it’s an ingenious and flexible way to allow for the consumption and traversal of network-available information. What it’s not, however, is a very good roadmap toward building APIs for web applications.
Is Real REST Too Hard?
Truly RESTful services simply require too much work to be practical for most applications. Too much work from the provider in defining and supporting custom media types with complex modeled relationships transmitted in-band. Too much work for clients and library authors to perform complex aggregation and re-formulation of data to make it conform to the real REST style. Real REST is great for generic, broad-encompassing multi-provider architectures that need the flexibility and discoverability it provides. For most application developers it’s simply overkilling and a real implementation headache.
There’s nothing wrong with the common definition of REST. It’s leaps and bounds better than some of the methods that came before it and pretty much everyone is already on board and familiar with how it works. It’s a pragmatic solution that really works pretty well for everyone. As they say, if it ain’t broke, don’t fix it.
What’s in a Name?
The only problem is that now we have lots of things that we’re calling REST that isn’t. Roy T. Fielding, a primary architect of HTTP 1.1 and the author of the dissertation that originally defines REST, hasnât always been happy with people calling things REST that isnât . And maybe he has a point: these services certainly aren’t REST by his definition and because of the wide propagation of this incorrect definition of REST most people now don’t really understand the true definition. In fact, I don’t claim to have a great understanding of REST as Dr. Fielding defines it.
The problem is that the ship has sailed, and whether it’s true or not, REST now also means any simple, URL-accessible resource-based service. Perception is reality, and perception has changed about the definition of REST and RESTful. While the true definition is interesting for academic purposes and certainly lies behind the technologies upon which we build every day, it simply doesn’t have a whole lot of use to web application developers. The fact that (nearly) zero services exist that implement true REST for their API serves as a testament to that.
What Can We Learn From REST?
Just because we don’t use true REST doesn’t mean there aren’t a few things we can learn from it. There are a few aspects that I’d love to see come into favor in the common definition. The idea of clients needing to know a few media types instead of specific protocols for each service is one that breaks down in practice for APIs due to the overwhelming number of web services with different needs in terms of domain-specific resource definition. However, wouldn’t it be great if there were an accepted application/x-person+json format that provided a standardized batch of user information (such as name, e-mail address, location, profile image URL) that you could request from Facebook, Twitter, Google or any OpenID provider and expect conforming data? Just because there are lots of domain-specific resources doesn’t mean that it isn’t worthwhile to try to come up with some standards for common information.
REST-like discoverability could also be a boon for some services. What if Twitter provided something like this along with a tweet’s JSON?
{
"actions": {
"Retweet" : { "method":"POST", url:"/1/statuses/retweet/12345.json" },
"Delete" : { "method":"DELETE", url:"/1/statuses/destroy/12345.json" },
"Report Spam" : { "method":"POST", url:"/1/statuses/retweet/12345.json", params:{"id":12345}
}
}So while REST as originally intended may not be a great fit for web applications, there are still patterns and practices to be gleaned from a better understanding of how such a service could work. For web applications, the case may be that REST is dead, long live REST!
You may find the original source here.
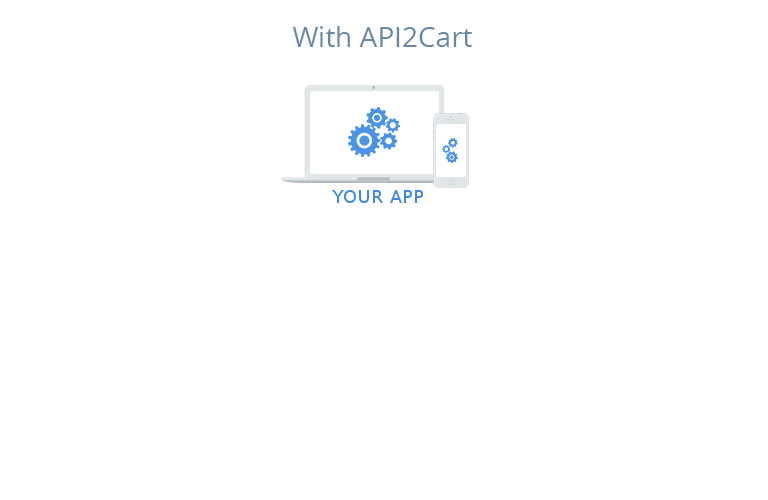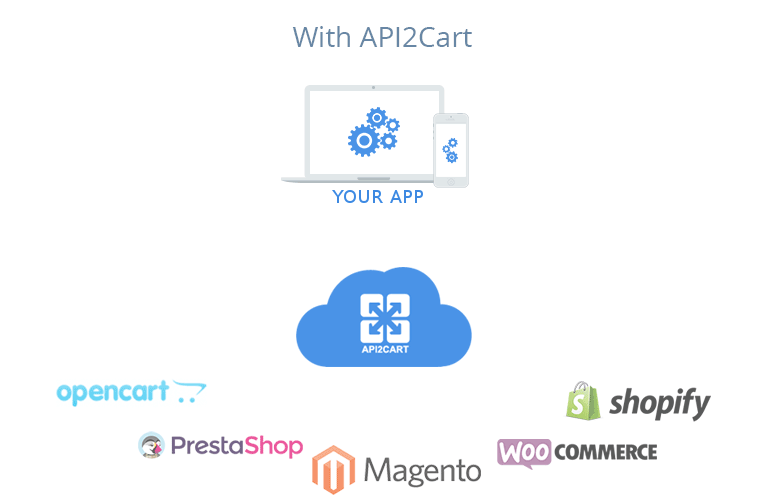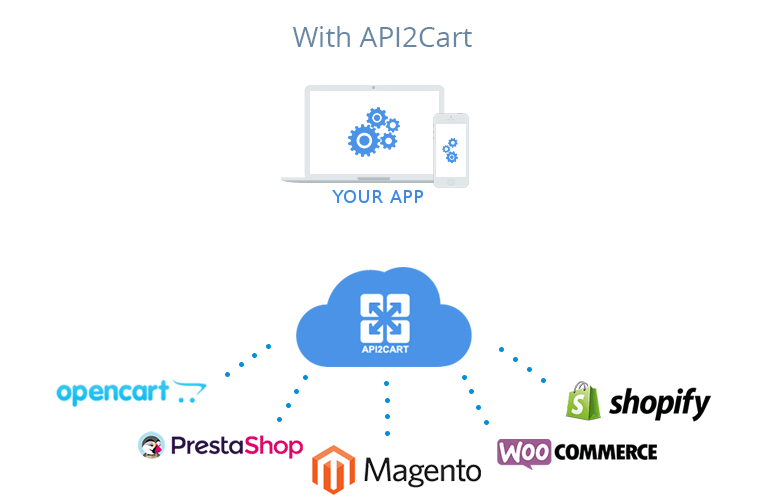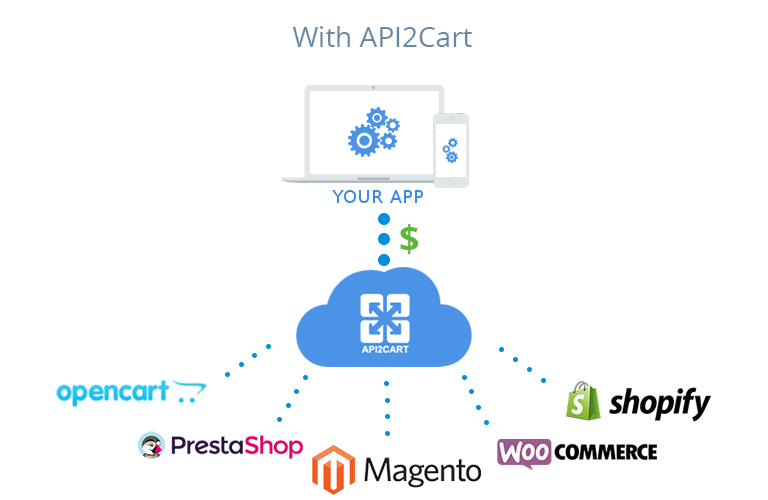
In case you are interested in integration with eCommerce platforms, try API2Cart. It provides a single API to work with more than 40 shopping platforms and marketplaces including Magento, Shopify, WooCommerce, BigCommerce, OpenCart, PrestaShop and others.
With API2Cart shopping platforms integration is easy
Integrate once, save 4-8 weeks and thousands of dollars on each integration.
Never worry about maintaining separate connections.