
You're probably dealing with this already. Orders arrive from one store with tax lines nested one way, another store sends discounts as negative adjustments, a third store leaves optional customer fields blank, and inventory updates race in after the catalog changed upstream. Nothing is technically “broken” at first glance, but downstream systems start drifting. Reports don't match the storefront. Fulfillment queues stall. Support asks why duplicate customers keep appearing.
That's where data validation automation stops being a hygiene task and becomes pipeline architecture.
For an integration developer in eCommerce, the job isn't just validating whether a field exists. The job is deciding what must be rejected immediately, what can be repaired safely, what should be retried, and what needs a human to inspect before it spreads into inventory, order management, finance, or analytics. Good validation prevents bad records from entering the system. Great validation keeps the whole integration operational under change.
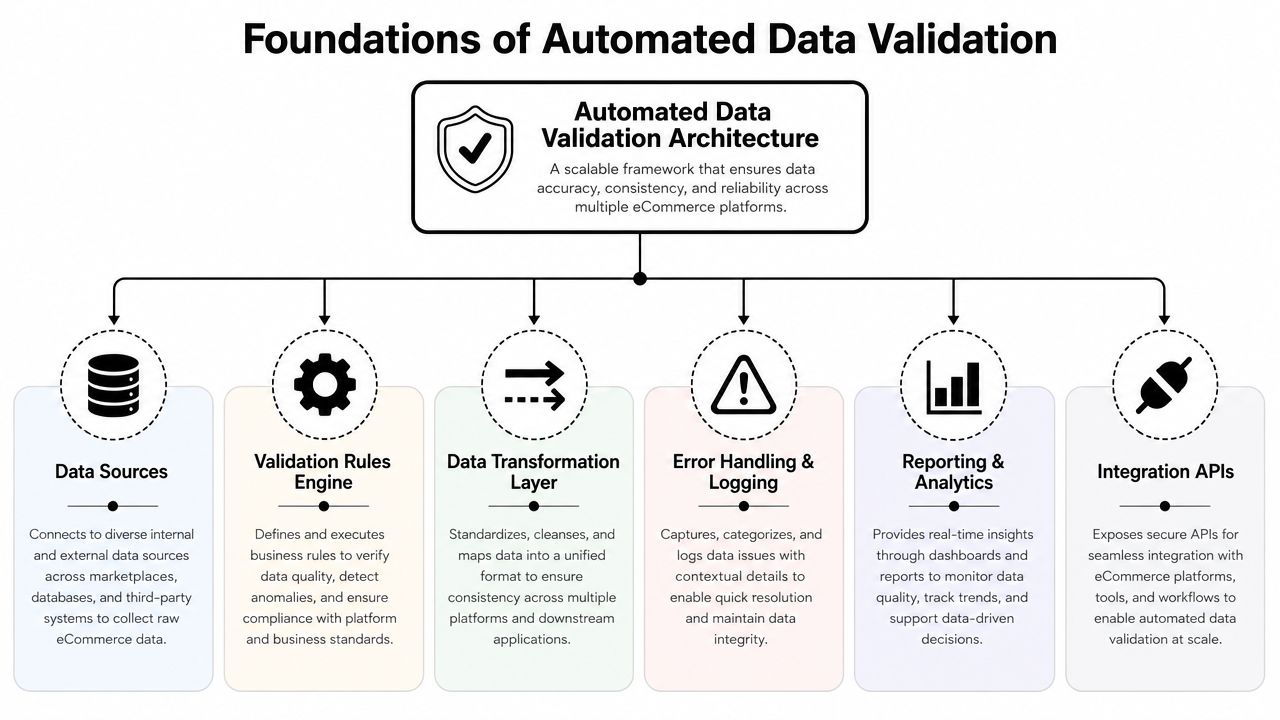
Foundations of Automated Data Validation
Modern data validation moved away from reactive cleanup and toward preventive control. Instead of fixing records after reports fail or sync jobs break, teams now use automated checks at entry, during transformation, and before output. That layered pattern is widely treated as the standard architecture because it catches issues earlier and more consistently than manual review, as described in this data validation and quality assurance overview.
In eCommerce, that shift matters because bad data rarely stays local. A malformed product payload can break search indexing. A duplicate customer can split order history. A missing SKU can turn a normal order into a fulfillment exception.
Four validation types you actually need
Schema validation checks whether the payload has the structure your pipeline expects. Is variants an array? Is created_at present in a parseable format? Did a platform start returning an object where your mapper expects a string?
Business rule validation asks whether the data makes sense in your domain. A refund can be negative. A product price usually can't. An order total below zero might be valid in a rare settlement workflow, but in most order import pipelines it should be flagged hard.
Deduplication protects the pipeline from repeated or overlapping records. Multi-channel systems often replay events, resend imports, or merge guest and registered customer identities badly. Without duplicate controls, you'll create noise that looks like growth until operations catches it.
Referential integrity confirms related records exist where they should. If an order line references a product_id, your catalog or product cache should know that item. If it doesn't, you haven't just found a bad field. You've found a broken dependency.
Validate in layers, not once
Single-point validation fails in production because each stage introduces different risks.
| Layer | What to validate | Typical failure |
|---|---|---|
| Ingress | Payload shape, required fields, basic type checks | Bad webhook body |
| Transformation | Mapping logic, normalized values, cross-field consistency | Wrong tax or currency mapping |
| Pre-load | Referential checks, duplicate detection, target constraints | Order loads before product sync |
Practical rule: reject early when the record can damage downstream state, but allow controlled warnings when the issue affects completeness more than correctness.
Developers who only validate schema usually end up with “valid” records that are still operationally wrong. Developers who only validate business logic usually discover too late that half the payload was malformed before rules even ran. You need both.
A useful mental model is to treat validation as a contract between systems, not a helper function inside a parser. That becomes more important in multi-store environments where mappings differ by merchant and fields evolve often. If you want a broader look at how AI validates data, it's a helpful companion to rule-based thinking, especially when you're dealing with anomaly detection alongside deterministic checks.
For developers building cross-platform commerce flows, the integration layer also needs a stable data access model. A unified commerce connection strategy, such as the one described in eCommerce data integration architecture, reduces how much platform-specific schema chaos leaks into your rule engine.
Designing Your Validation Rulebook
A rulebook is executable policy. If the policy lives only in tickets, tribal memory, or a spreadsheet no one updates, your pipeline will drift.
Automation matters because volume arrives faster than a developer can inspect manually. One industry guide says AI-driven validation can handle “thousands of records in seconds” while catching duplicates, incorrect formats, missing data, and inconsistencies, which is why rule design has to stay efficient and precise from the start, as noted in this automated data validation guide.
Start with rules that map to real failure modes
Below is the kind of rulebook I'd want in place before turning on a broad product and order sync.
Schema rule for product payloads
A product without variants may be valid on some platforms, but if your downstream catalog model requires a variant array, make that explicit.
rule product_variants_present:
when entity_type == "product"
assert field_exists("variants")
assert is_array("variants")
on_fail:
severity = "hard"
code = "SCHEMA_MISSING_VARIANTS"
This catches a common integration mistake. The upstream payload exists, your parser doesn't crash, but your transformation later assumes sellable units live under variants[]. Without a hard failure, you'll import incomplete catalog data without immediate warning.
Business rule for suspicious orders
Now take an order feed from a storefront where discounts, refunds, and taxes can appear in separate structures.
rule order_total_non_negative:
when entity_type == "order" and status not in ["refunded", "cancelled"]
assert total >= 0
on_fail:
severity = "hard"
code = "BUSINESS_NEGATIVE_TOTAL"
That rule isn't universal. It depends on your commerce model. The important part is documenting the exception path. If refunded orders can be negative, encode that. Don't make the operations team infer your intent from rejected records.
A good validation rule doesn't just say what failed. It says what business assumption was violated.
Deduplication logic for customers
Customer duplication gets ugly fast because stores differ in how they represent identity. Emails vary in case. Phone numbers contain formatting noise. Guest checkout creates partial records.
rule customer_duplicate_check:
normalized_email = lower(trim(email))
normalized_phone = digits_only(phone)
duplicate_key = first_non_empty(
normalized_email + "|" + normalized_phone,
normalized_email,
normalized_phone
)
assert not exists_in_identity_index(duplicate_key)
on_fail:
severity = "warning"
action = "merge_candidate"
Notice the severity. Duplicate customers don't always justify dropping the record. Often you want to quarantine it or route it into a merge workflow rather than block imports.
Referential integrity for order lines
Often, many integrations fail after looking healthy in logs.
rule order_line_product_reference:
when entity_type == "order_line"
assert exists_in_catalog_cache(product_id)
on_fail:
severity = "hard"
code = "MISSING_PRODUCT_REFERENCE"
action = "retry_after_catalog_sync"
That last action matters. If product sync lags behind order sync, the record may be valid but out of sequence.
What works better than giant rule files
Large monolithic rule sets become impossible to maintain. Split them by domain:
- Catalog rules for products, variants, attributes, images
- Order rules for totals, line items, addresses, taxes
- Customer rules for identity, dedupe, consent, segmentation
- Sync rules for versioning, sequencing, replay, source freshness
Keep each rule tied to an owner, a severity, and a remediation path. If a rule can fail but no one knows what to do next, it isn't operationally complete.
Real-Time vs Batched Validation Workflows
The timing of validation changes the shape of the whole system. In eCommerce, organizations often use both patterns because different entities have different tolerance for latency.
Real-time validation is best when the business consequence of delay is immediate. Batched validation is better when throughput, sequencing, and controlled retries matter more than instant response.
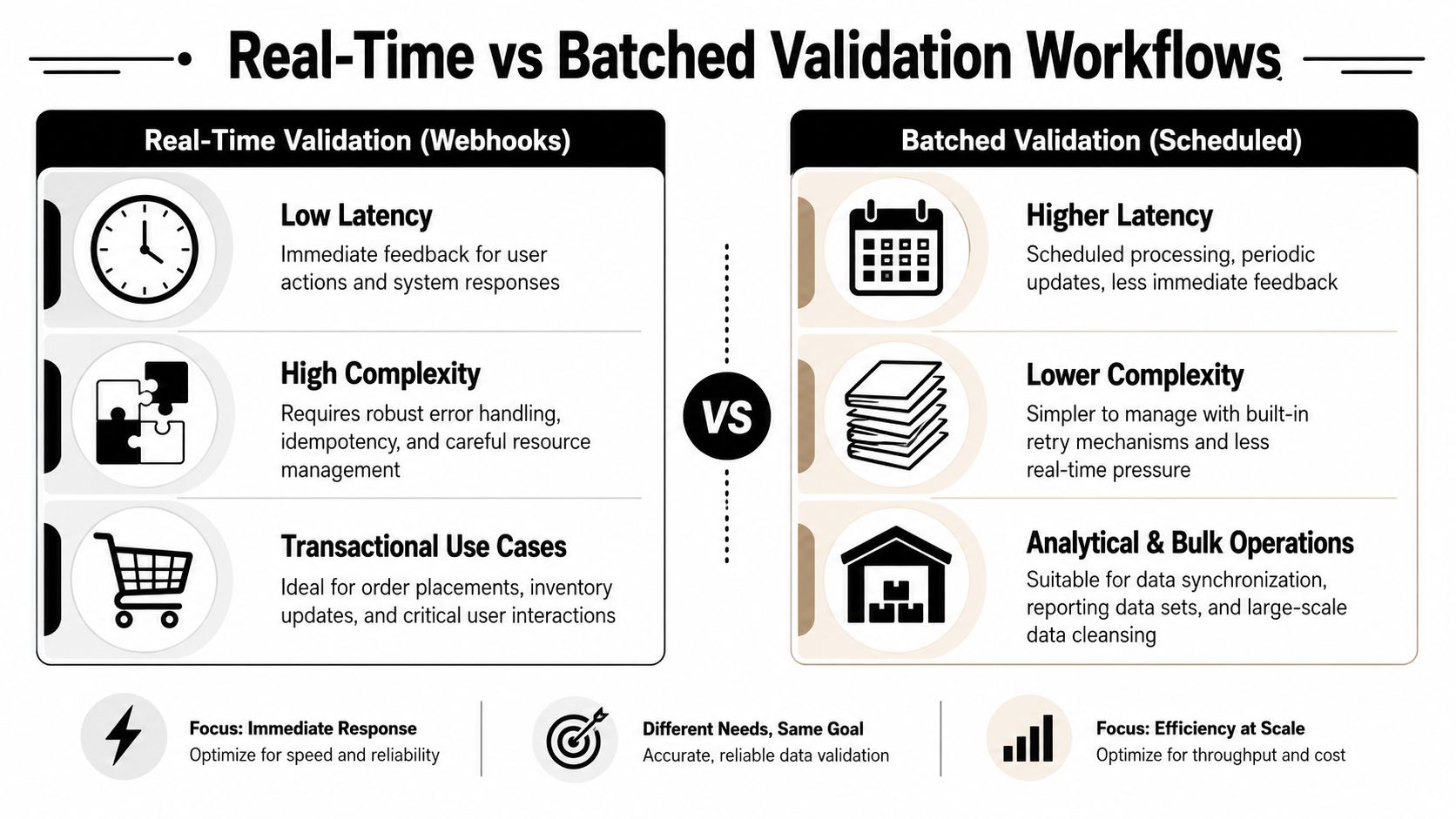
Real-time workflow with webhooks
When an order is placed, a webhook can trigger validation immediately. That gives you a chance to reject malformed records before they contaminate fulfillment or finance.
Real-time works well for:
- Order intake where invalid address or item structure should be caught fast
- Inventory updates where stale stock can cause overselling
- Customer events where follow-up automation depends on accurate identity data
But it comes with pressure. Your endpoint must stay available. Your validator must respond quickly. Your retry handling must tolerate duplicate delivery.
A webhook-based validator should separate response speed from deep processing. Acknowledge receipt once the event is durably stored and passes minimal gate checks. Then run heavier validation asynchronously. If you do all business logic inline, you turn upstream instability into your incident.
For developers thinking through immediate versus delayed checks, some of BillionVerify's email validation insights are useful because the same design tension applies here. Fast feedback helps user-facing workflows. Bulk processing is often better for large backfills and periodic cleanup.
Batched workflow with polling
Polling is usually the safer choice for bulk syncs and nightly reconciliation jobs. You fetch records by date window or cursor, run validations in groups, retry transient failures, and produce exception reports.
This model fits:
| Workflow | Best fit | Main trade-off |
|---|---|---|
| Webhooks | Event-driven order and inventory changes | More operational complexity |
| Polling | Backfills, reconciliations, bulk catalog updates | More latency |
Polling gives you more room to classify errors. One malformed record doesn't need to poison the whole batch. You can skip, quarantine, or retry a subset.
The downside is freshness. A batched validator may mark inventory as valid when it already changed upstream between runs. That's acceptable for some analytics flows. It's not acceptable for time-sensitive commerce actions.
Pick based on consequence, not preference
A lot of integration teams choose workflow style based on what's easier to code. That's the wrong criterion. Choose based on the cost of delay and the cost of false acceptance.
Use real-time validation when bad data can trigger an immediate business error. Use batched validation when consistency across many records matters more than sub-second feedback.
A hybrid approach is usually strongest. Real-time for event capture and hard gate checks. Batched for reconciliation, enrichment, and drift detection. If your integration stack supports both event-driven and scheduled sync patterns, a unified synchronization layer like real-time API synchronization for commerce data makes it easier to apply the same validation policy across both paths.
Building Resilient and Idempotent Systems
Validation without resiliency looks fine in staging and falls apart in production. Networks time out. Upstream systems resend events. A store saves a partial product, then patches it moments later. If your validator can't survive those conditions, it becomes a source of incidents instead of a control.
The most important property here is idempotency. If the same order event arrives three times, your system should produce the same end state as if it arrived once.
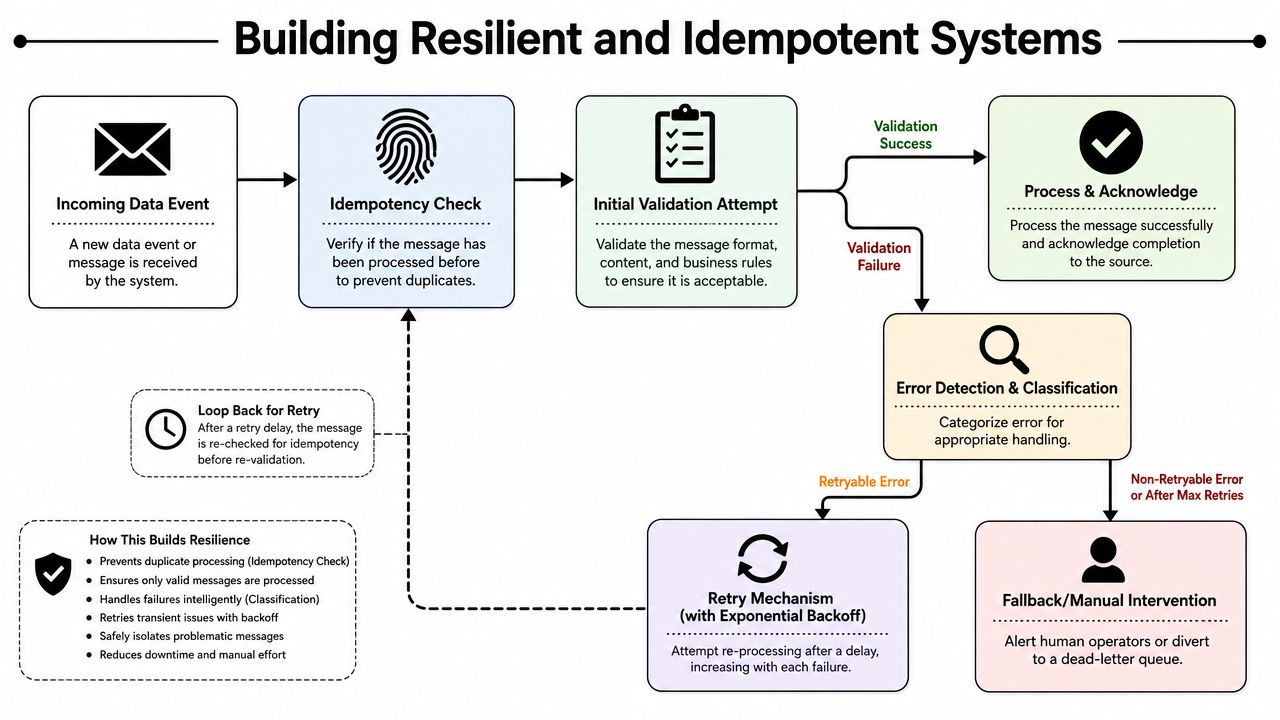
Idempotency first, retries second
A retry strategy without idempotency creates duplicate writes and conflicting state. Store a deterministic processing key for each event or record. That key might come from an external event ID, a composite business identifier, or a canonical hash of the relevant payload.
Once you have that, retries become safe.
A practical flow looks like this:
- Receive event
- Check idempotency key
- Skip if already processed successfully
- Run validation
- Classify failure as retryable or terminal
- Retry transient failures with backoff
- Route terminal failures to quarantine or manual review
Classify failures like an operator would
Not every validation failure deserves the same treatment.
- Retryable failures include temporary API unavailability, missing upstream dependency that may appear shortly, or short-lived fetch errors.
- Terminal failures include malformed required fields, impossible data types, and broken business rules that won't improve on retry.
- Soft failures include optional data gaps that reduce completeness but don't threaten correctness.
That last category matters more than is often acknowledged. Thresholds keep your alerts useful. Sigma specifically notes that a few nulls in a rarely used field may not matter and recommends threshold-based alerts so teams don't get overwhelmed by noise, as described in this guidance on automating data validation.
If every warning pages the team, the team stops trusting the alerts.
What operationally useful alerting looks like
Don't send the same notification for every failure class. Use a severity ladder.
| Severity | Example | Response |
|---|---|---|
| Info | Optional marketing field missing | Log and summarize |
| Warning | Duplicate customer candidate | Route to review queue |
| Critical | Order line references missing product | Page on-call and pause affected flow |
Many validation systems ultimately become unusable. They technically detect problems but create so much alert noise that no one can tell the difference between a harmless schema wobble and a business-stopping defect.
Use dead-letter queues for non-processable records. Keep the original payload, validation errors, store metadata, and processing attempts together. That gives developers enough context to reproduce and fix the issue without guessing.
Exponential backoff also needs boundaries. Unlimited retries hide real defects. A retry budget forces the system to promote unresolved errors into an inspectable state.
Accelerating Integration with API2Cart
Multi-platform eCommerce validation gets expensive before the rule engine even starts. Each platform has different payload conventions, field naming patterns, pagination behavior, webhook support, and update timing. If your team writes custom connectors one by one, most of your validation effort gets consumed by connector variance instead of business correctness.
That's why unified access matters. The hard problem isn't just validating fields. It's keeping your validated view aligned with live upstream systems that keep changing.
Why source drift breaks static validation
A record can pass every format and range check you wrote and still be wrong in practice. The upstream product may have changed title, stock, visibility, or price after your last sync. The order may still be syntactically valid while no longer matching the source of truth.
That's the practical issue behind validation against live upstream sources. Static checks don't solve staleness. A unified API helps by giving your pipeline a consistent, near-real-time view across multiple systems, reducing the risk that your “validated” copy has already drifted away from what's current upstream, as discussed in this article on data validation testing and source drift.
What a unified commerce API changes for developers
For an integration developer, the gains are architectural:
- One normalized access layer means your schema rules target a stable model instead of dozens of platform-specific payloads.
- Shared sync patterns let you apply the same validation lifecycle to products, orders, customers, and inventory.
- Centralized event and polling support reduces custom code around when and how you fetch records for validation.
- Less connector churn means more time spent on business rules and failure handling.
This isn't just about faster initial development. It improves maintainability. Rulebooks become more portable. Test fixtures become reusable. Monitoring becomes clearer because error categories don't fragment across every connector.
The fastest way to reduce validation complexity is to reduce schema variability before records hit your rule engine.
Documentation quality also matters here. If your integration contract and payload model drift from implementation, validation logic starts breaking in subtle ways. A useful reference on keeping API documentation aligned is GitDocAI for auto-synced docs, especially if your team maintains internal schemas and generated clients.
If you want to understand the architectural case for a normalized commerce access layer, this overview of a unified API model is directly relevant. The key developer takeaway is simple: standardize the ingress model first, then invest in richer validation logic on top of that stable surface.
Testing Monitoring and Operational Runbooks
Validation code needs the same discipline as any other production system. If you only test the happy path, your first real schema change or upstream outage will become the test environment.
A strong rollout follows a staged path: define rules first, run unit and integration tests, pilot on non-critical data, monitor error rates in real time, and keep rollback procedures ready. That staged methodology is recommended because it exposes defects before broad deployment and creates a feedback loop for updating rules, as described in this rollout guide for automated data validation.
Test the rules in layers
Don't rely on end-to-end tests alone. Most validation defects are easier to isolate earlier.
Unit tests
Test individual rules with focused fixtures.
- Schema tests should verify missing required fields, wrong types, empty arrays, and unexpected nesting.
- Business rule tests should include boundary cases, exception states, and contradictory field combinations.
- Deduplication tests should verify normalization logic across case changes, formatting differences, and partial identities.
Integration tests
Run payloads through the full mapping and validation pipeline using store-like samples. Include edge cases such as partial updates, delayed dependencies, and replayed events.
Performance tests
Validation can become the bottleneck if rules are too chatty or require expensive cross-record lookups. Load test your validation path with realistic bursts, especially around product imports, flash-sale order spikes, and large catalog refreshes.
Monitor the signals that reveal drift
A dashboard full of generic “error count” charts won't help much. Track metrics that tell you where and why validation is weakening.
| Metric | Why it matters |
|---|---|
| Validation error rate by platform | Reveals connector-specific drift |
| Rule execution latency | Shows whether validation is becoming a throughput bottleneck |
| Quarantine or dead-letter volume | Identifies unresolved failure accumulation |
| Retry success pattern | Separates transient instability from bad data |
| Top failing rules | Exposes outdated assumptions in the rulebook |
You also want store-level segmentation. One merchant's custom setup can generate chronic warnings that shouldn't distort the overall picture.
Keep an on-call runbook short and concrete
When alerts fire, responders need action steps, not theory.
A minimal runbook should answer:
- What failed? Rule name, entity type, affected store, severity.
- Is this isolated or widespread? Check platform, merchant group, and recent deploy history.
- Can the flow continue safely? Decide whether to pause, degrade, retry, or quarantine.
- What changed? Compare current payload shape and recent schema assumptions.
- How do we recover? Replay from queue, rerun batch window, or backfill corrected records.
Keep the first-response decision tree boring. The more improvisation you require during an incident, the longer bad data sits in motion.
Rollbacks also need discipline. If a new rule starts blocking valid traffic, disable the rule or downgrade severity without tearing down the whole pipeline. Fine-grained controls make validation safer to evolve.
Frequently Asked Questions
The hardest validation problems usually appear after the first launch. Rules that looked solid on day one start failing because stores customize fields, platforms evolve payloads, and business logic gets more nuanced.

How should I handle schema changes without breaking the pipeline
Treat schema evolution as normal, not exceptional. Version your contracts where possible, keep parsers tolerant of additive fields, and fail only when a removed or reshaped field breaks a required assumption.
Use canary validation on a subset of traffic before promoting new schema expectations broadly. If a platform starts returning a different structure for addresses or product options, you want that surfaced as a targeted compatibility issue, not a full import outage.
Should custom merchant fields be hard-validated
Usually no, at least not by default.
Merchant-defined fields are where rigid validation causes the most friction. Validate the container structure and basic type safety, then apply merchant-specific rules only if your application depends on those fields. Otherwise, store them as flexible attributes and validate them at the feature boundary where they become operationally important.
Can I automate rule creation
Partially. You can infer candidate schema rules from observed payloads and detect anomalies when records diverge from established patterns. But generated rules still need human review.
Business rules are where automation alone falls short. A machine can notice that a field changed distribution. It can't reliably decide whether a negative amount is a valid refund scenario or a mapping bug without domain context.
When should a validation failure block processing
Use hard validation when accepting the record can corrupt state, trigger bad business actions, or make recovery harder. Use soft validation when the data is imperfect but still safe to process.
Examples:
- Hard fail for missing order line references, invalid quantities, or malformed identifiers used as primary keys.
- Soft fail for missing optional profile fields, non-critical metadata gaps, or enrichment mismatches.
The split should follow operational consequence, not developer preference.
Is high agreement enough to trust automation long term
No. One real-world example reported a 99% import success rate after strong schema enforcement and validation, but research still emphasizes that continuous validation of the logic is necessary as data sources and business needs evolve, as noted in this data validation example and reliability discussion.
That's the part teams often miss. High performance at launch doesn't remove the need for maintenance. It increases it, because success makes the pipeline more central to the business.
What's the biggest mistake in data validation automation
Treating it as a feature instead of an operating system for your integration.
A feature mindset leads to static rules, weak alerting, and poor recovery paths. An operational mindset leads to layered checks, idempotent processing, threshold-based notifications, staged rollout, and regular rule review. That's what keeps multi-platform commerce data usable under change.
If you're building commerce integrations and want to reduce connector-specific validation work, API2Cart gives your team a unified way to access store, order, product, customer, and inventory data across many shopping carts and marketplaces. That means less time normalizing platform differences by hand, and more time building the validation, monitoring, and recovery logic that protects your pipeline.



