
You're probably dealing with some version of this already.
An order lands in an eCommerce store. Your app needs to reserve inventory, update a warehouse record, sync the order to an ERP, and maybe trigger shipping logic. One API call succeeds. Another times out. A third returns later with a retry. Now you've got stock reduced in one place, unchanged in another, and a support ticket waiting by morning.
That's the distributed transaction problem in practical clothes.
The Two-Phase Commit Protocol is one of the oldest and clearest answers to that problem. It gives multiple systems a way to agree on one atomic outcome. Either everyone commits, or everyone backs out. For an integration developer, that idea matters even if you never implement a full transaction manager yourself. It shapes how you think about stock sync, order import, payment coordination, and recovery after failure.
Why Atomic Transactions Matter in eCommerce
A lot of integration bugs don't start as coding mistakes. They start as split outcomes.
Say your system receives a request to move inventory after an order is paid. You update the warehouse management system first. That succeeds. Then you push the new stock level to the storefront, and that call fails. Customers still see the old availability, but your warehouse has already reduced stock. The business now has a mismatch, and your team has to decide which system is “right.”
That's why atomicity matters. An atomic operation behaves as one indivisible unit. Either the whole business action happens, or none of it does.
In eCommerce, this shows up everywhere:
- Inventory synchronization between a storefront and a fulfillment system
- Order creation across sales, warehouse, and accounting components
- Catalog updates that need to land consistently across channels
- Refund or cancellation flows that must reverse related changes together
If you work with product and inventory data across channels, good software for product catalog management also helps reduce inconsistency at the data layer before transaction logic even enters the picture.
Where developers get burned
The confusion usually comes from thinking in API calls instead of business actions.
A business action is “transfer 3 units from available stock to reserved stock across connected systems.”
An API action is “POST to service A, then PATCH service B, then notify service C.”
Those aren't the same thing. A sequence of successful HTTP requests doesn't automatically create a safe business transaction.
Practical rule: If partial success would create a support issue, accounting issue, or inventory issue, you're dealing with a transaction problem, not just an API workflow problem.
The reason the Two-Phase Commit Protocol still gets taught is simple. It has been used in enterprise software systems for over three decades, and its all-or-nothing model remains the standard way to coordinate distributed atomic transactions across multiple partitions or shards, as discussed in this explanation of 2PC's long-standing role in database systems.
The core promise of 2PC
Two-phase commit gives you a strict guarantee: one participant can veto the entire operation.
That sounds harsh, but it's exactly what preserves consistency. If one system can't safely complete its part, the whole transaction aborts. In an inventory transfer, that means you don't withdraw from one account of record and fail to deposit into another. In eCommerce terms, you don't reserve stock in one backend while leaving the selling channel unchanged.
That guarantee is powerful. It's also expensive, which is why you need to understand both the mechanics and the trade-offs.
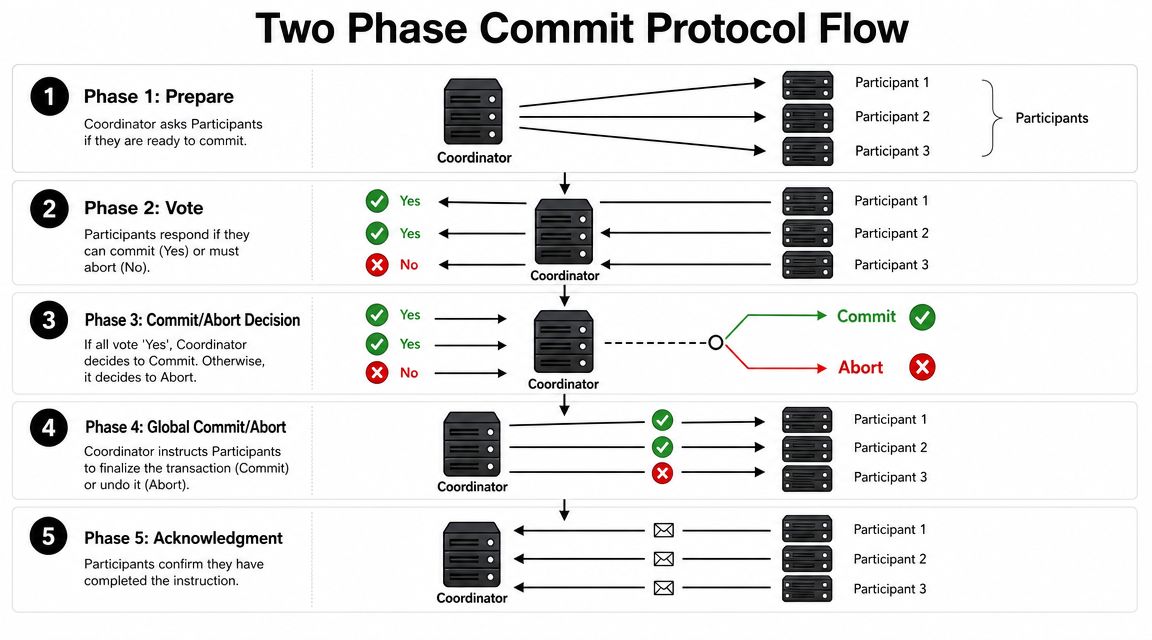
Understanding the Two Phase Commit Protocol Flow
The easiest way to understand the Two-Phase Commit Protocol is to think in terms of roles.
There's a coordinator and there are participants. The coordinator doesn't do all the work itself. It asks each participant whether it can complete its part safely, then makes one final decision for everyone.
A useful analogy is a wedding officiant. The officiant asks whether the ceremony can proceed. If every required party is ready, the ceremony continues. If one required party says no, the process stops. The officiant doesn't partially complete the wedding.
Phase 1 prepare and vote
The first phase is often called prepare or vote.
The coordinator sends a message to each participant asking, in effect, “Can you commit this transaction if I tell you to?” A participant doesn't answer casually. Before it says yes, it has to make sure it can finish the work later.
According to the standard description of 2PC mechanics, the protocol achieves atomicity by splitting the process into a prepare/vote phase and a commit/abort phase, with each participant first confirming it can durably complete the work, typically by writing log records and acquiring locks, before the coordinator issues the final decision.
For an integration developer, that means a participant usually does things like:
- Validate the request. Is the inventory available? Is the order state valid?
- Acquire what it needs. That may include locks or reserved resources.
- Write recovery information. If the service crashes, it must know what state it had reached.
- Return its vote. Yes if it can commit later. No if it can't.
Phase 2 commit or abort
Once the coordinator has all votes, it decides.
If every participant voted yes, the coordinator sends a global commit. If even one participant voted no, the coordinator sends a global abort.
That all-or-nothing decision is the heart of the protocol.
Here's the flow in plain language:
| Step | Coordinator action | Participant action |
|---|---|---|
| Prepare | Ask each system if it can commit | Validate, lock, log, vote |
| Decision | Evaluate all responses | Wait for final outcome |
| Finalize | Send commit or abort to all | Complete or roll back |
| Confirm | Record completion | Acknowledge result |
A concrete eCommerce example
Suppose your app is coordinating a stock reservation across two internal services:
- a catalog service that exposes available quantity
- a warehouse service that manages physical allocation
The coordinator asks both services to prepare.
The catalog service checks whether the requested quantity can be reserved and records that intent. The warehouse service checks whether picking capacity and stock location are valid and records its own prepared state.
Now two outcomes are possible:
- Both vote yes. The coordinator sends commit. Both services finalize.
- One votes no. The coordinator sends abort. Neither service makes the business change permanent.
Once a participant votes yes, it has effectively promised it can commit later if told to do so. That's why the prepare step is much heavier than a simple validation call.
Why this guarantees atomicity
The coordinator doesn't let systems drift into independent outcomes. It forces one shared decision.
That's what makes 2PC easy to reason about. You can trace every transaction through a narrow set of states: preparing, prepared, committed, or aborted. For teams integrating multiple business systems, that state discipline is often more useful than the protocol's formal terminology.
The Hard Truth About 2PC Performance and Failures
The Two-Phase Commit Protocol is elegant on paper and demanding in production.
Its central weakness is that it's a blocking protocol. Once a participant has voted yes, it can't just change its mind and move on. It has to wait for the coordinator's final decision. During that wait, it may be holding locks, reserved resources, or transaction state that prevents other work from proceeding.
That's where the pain starts.
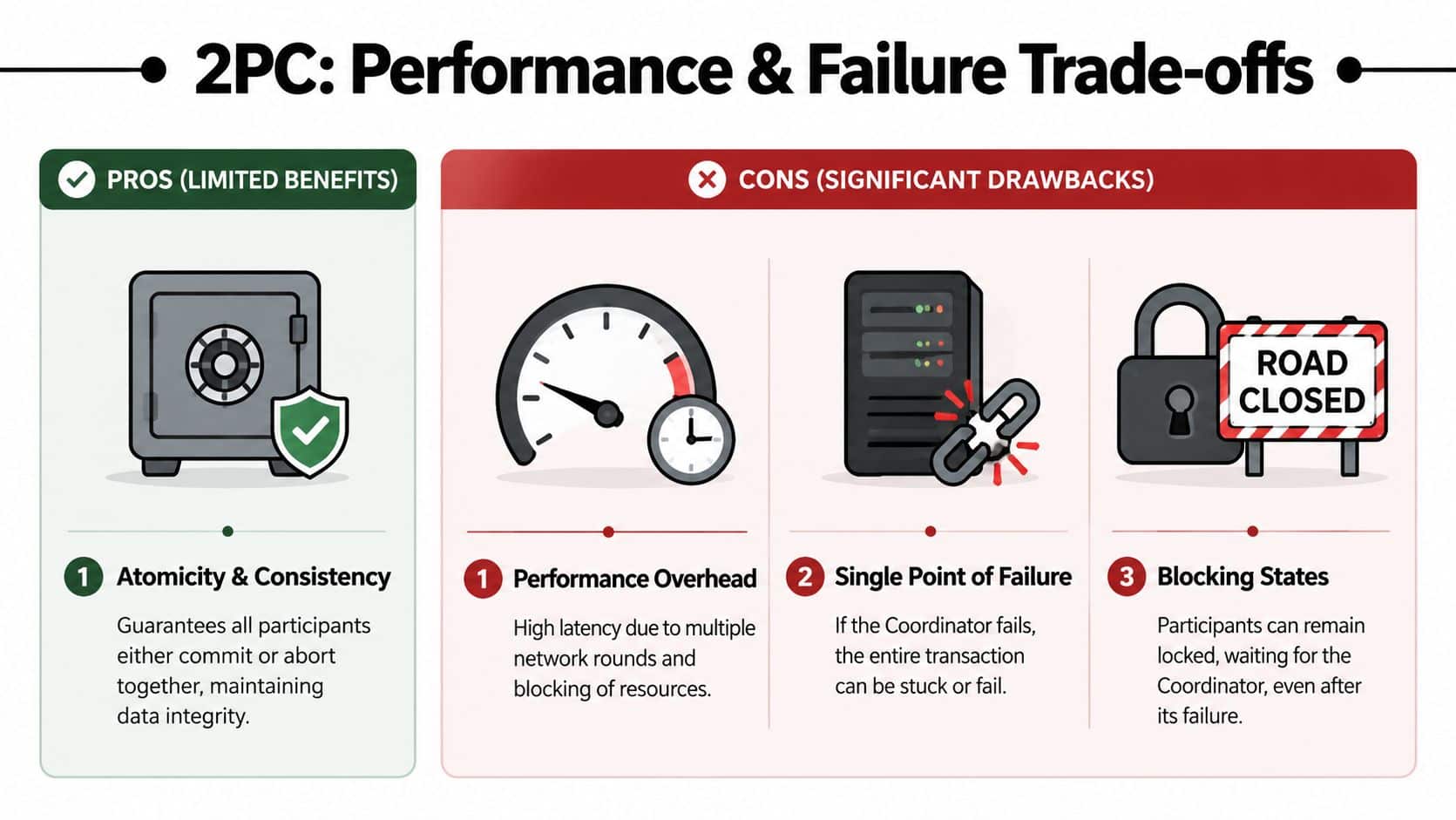
Why blocking becomes a real problem
This isn't just a theoretical edge case. Martin Fowler's write-up on two-phase commit notes that participants that have voted yes must wait for the coordinator's final decision, holding locks and relying on write-ahead logging. That waiting behavior explains the protocol's well-known latency and scalability penalty in distributed transactions with many participants.
In practice, the trouble usually appears in one of these forms:
- Coordinator failure: Participants are prepared and waiting, but nobody can tell them to commit or abort until recovery happens.
- Slow network links: The transaction remains open longer than expected, which stretches lock duration.
- Many participants: The coordinator has to gather more votes and deliver more final decisions, which increases coordination overhead.
- Retry storms: If surrounding services retry aggressively, the blocked transaction creates additional contention.
What failure looks like in an integration system
Think about a multi-step order flow.
Your orchestration service sends prepare requests to inventory, warehouse, and finance subsystems. Inventory and warehouse vote yes. Then the coordinator process crashes before sending the final decision.
Now those two participants are stuck in a prepared state. They can't assume commit, because that might violate atomicity. They can't assume abort, because the coordinator might already have decided commit and just failed before notifying them. So they wait.
That waiting can ripple outward. Other operations that need the same stock records or warehouse rows may now queue behind the prepared transaction.
A system can be logically correct and still be operationally painful. That's the story of 2PC in many modern architectures.
Why high-throughput SaaS teams often avoid it
The issue isn't that 2PC is broken. The issue is that it trades throughput and availability for strict coordination.
For an integration developer, this trade-off becomes obvious when external APIs enter the picture. Remote platforms have their own availability windows, timeout behavior, rate limits, and retry semantics. If you try to force a strict distributed commit model across systems you don't control, you inherit all of their timing and failure characteristics.
That's why API consumption patterns matter. If your integration already struggles with request ceilings or delayed retries, API rate limit behavior in distributed integrations should be part of your architecture review. Tight transaction windows and constrained API throughput don't work well together.
A practical test
Use this simple question:
| If this is true | 2PC becomes harder to justify |
|---|---|
| Participants are external APIs | Yes |
| Network reliability varies | Yes |
| Transactions span many systems | Yes |
| Long-held locks hurt throughput | Yes |
| Immediate consistency is legally or financially required | Maybe still worth it |
The protocol gives you strong atomicity. It also gives you waiting, lock retention, recovery complexity, and sensitivity to the slowest participant.
That is the bargain.
Implementing 2PC Concepts in Your Integrations
Most integration developers won't build a full Two-Phase Commit Protocol stack from scratch. You'll still benefit from its design rules because the same failure modes show up in everyday API orchestration.
Three ideas matter more than anything else: idempotency, timeouts, and durable state tracking.
Idempotency first
A commit or abort message may arrive more than once. A network retry might repeat the same request after the participant has already processed it. If your handler treats duplicates as new work, you can create double updates or contradictory rollback behavior.
Make your state transitions idempotent.
If a participant already marked transaction T123 as committed, a repeated commit for T123 should return success without doing the business action again. The same goes for abort.
A simple pattern is to persist transaction state by transaction ID and reject invalid transitions.
Timeouts prevent endless waiting
Prepared states can't remain open forever.
Even if you aren't implementing strict 2PC, your orchestration layer should define clear timeout behavior for “waiting for confirmation” states. A timeout doesn't magically resolve consistency, but it gives your system a deterministic path: retry, escalate, compensate, or move to manual review.
Use different timeouts for different stages:
- Short timeout for initial request/response communication
- Longer timeout for downstream completion when the remote side has accepted work
- Recovery timeout for jobs that need operator attention or delayed reconciliation
Don't confuse a network timeout with a business abort. The first means you don't know. The second means you do.
Durable logging is your recovery tool
Prepared work without durable state is dangerous. If your service crashes, it needs to know whether it had accepted a transaction, sent a commit, received an abort, or was still undecided.
At minimum, store:
- Transaction ID
- Current state
- Participant or step name
- Last outbound command
- Last inbound acknowledgment
- Recovery timestamp
That record becomes your source of truth during restart or reconciliation.
Small pseudocode pattern
begin transaction(txId)
record state = PREPARING
if !participantA.prepare(txId):
record state = ABORTED
participantA.abort(txId)
participantB.abort(txId)
return failure
if !participantB.prepare(txId):
record state = ABORTED
participantA.abort(txId)
participantB.abort(txId)
return failure
record state = COMMITTING
participantA.commit(txId)
participantB.commit(txId)
record state = COMMITTED
return success
This is simplified, but the engineering lessons are real:
- record state before critical transitions
- retry safely
- design commit and abort handlers to tolerate duplicates
- treat recovery as part of the design, not cleanup work
If you carry those habits into your integrations, you'll avoid many partial-failure bugs even without formal 2PC infrastructure.
How Unified APIs Abstract Away Integration Complexity
The hardest part of distributed coordination in eCommerce usually isn't the theory. It's the number of systems involved.
A SaaS team might need to sync orders, products, prices, customers, shipments, and inventory across many commerce platforms and marketplaces. Each one has its own authentication rules, API quirks, object model, error format, pagination pattern, and retry behavior. Even before you think about transaction semantics, you're already maintaining a large compatibility surface.
That's why many integration teams stop trying to model these connections as one-off direct contracts. They use a unified abstraction layer instead.

What abstraction changes for the developer
A unified API doesn't eliminate distributed systems reality. It contains it.
Instead of writing custom logic for each storefront or marketplace, your application talks to one normalized contract for common operations like product sync, order import, shipment updates, or stock changes. That means your team can centralize:
- Error handling rules
- Retry and backoff logic
- Field mapping
- Authentication flows
- Webhook and polling strategy
- Recovery processes for partial failures
If you're evaluating architecture at that level, this overview of what a unified API means for multi-platform connectivity is useful context.
Why this matters in day-to-day eCommerce work
Suppose your app needs to push stock updates to many merchant stores. If you build every connector yourself, you're also signing up to normalize status codes, reconcile asynchronous updates, and handle platform-specific edge cases when requests fail halfway through a business process.
A unified API shifts the integration problem upward. Your team can focus on business intent, such as “update inventory for this merchant,” rather than connector-specific plumbing.
That approach is especially helpful for developers working on Shopify-heavy ecosystems, where app logic often expands from one store integration into broader omnichannel workflows. Teams planning that path often benefit from reading about optimizing Shopify with integrations because it highlights the operational cost of stitching services together one connector at a time.
The practical takeaway
For an integration developer, the value isn't that a unified API magically turns every remote update into a perfect atomic transaction.
The value is that it reduces how much low-level coordination logic your own team has to own.
The best integration architecture is often the one that removes custom failure handling from your backlog, not the one with the most theoretically pure transaction model.
That matters when you're building a product, not a distributed systems research project.
Exploring Modern Alternatives to Two Phase Commit
Strict atomic coordination isn't the only way to build reliable distributed workflows.
Modern architecture tends to treat 2PC as something to use carefully, not automatically. Recent technical writing on non-blocking 2PC variants and alternatives frames classic 2PC as a blocking protocol that constrains availability and scalability, which is one reason developers increasingly prefer patterns that minimize its use.
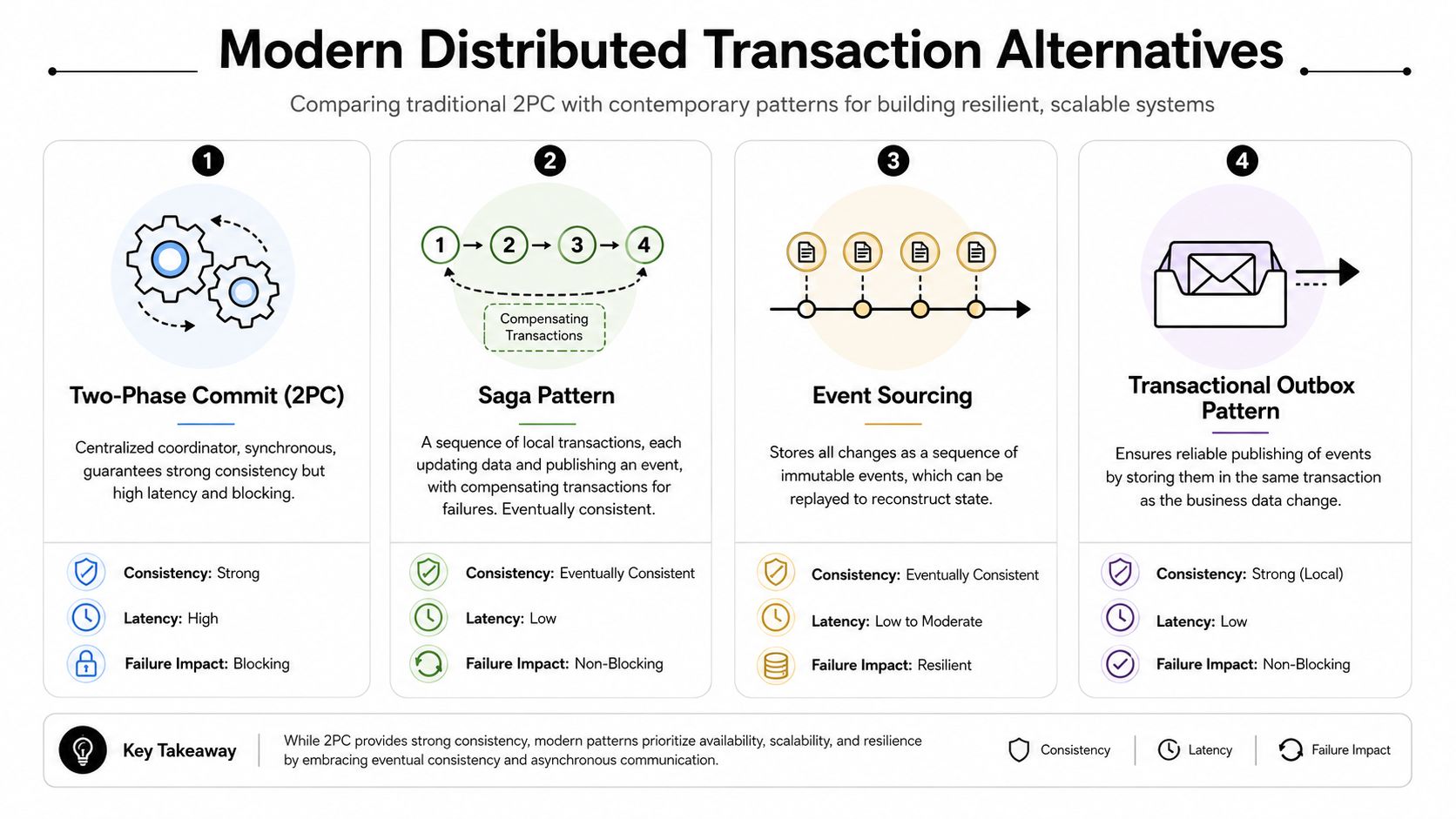
Saga pattern
A Saga breaks one distributed business process into a sequence of local transactions.
Each step commits inside its own service boundary. If a later step fails, the system runs compensating actions to undo the business effect of earlier steps. In eCommerce, that might mean creating an order, reserving stock, then issuing a compensating stock release if payment later fails.
This model is often easier to operate when availability matters more than immediate global consistency.
Transactional outbox and event-driven coordination
Another common approach is the transactional outbox pattern.
A service writes its business change and the outgoing event record in the same local transaction. A background process then publishes that event reliably. This avoids the fragile “save database state, then separately try to publish a message” sequence.
For integration teams deciding between polling and event-driven sync, understanding webhooks versus APIs in integration design helps because delivery style affects how you model retries, ordering, and reconciliation.
Event sourcing
With event sourcing, the system stores immutable events rather than only current state.
That doesn't solve distributed transactions by itself, but it changes the recovery model. You gain a durable history of what happened and can rebuild state from the event stream. For workflows with complex audits or replay needs, that can be more valuable than trying to coordinate one global commit across many services.
What about 3PC, Paxos, and Raft
You'll also hear about Three-Phase Commit, which tries to reduce blocking by adding another phase. It's part of the history of distributed transaction design, but it's not the default answer for most integration work.
Paxos and Raft solve a different problem. They help a cluster agree on a replicated log or leader-driven state changes. They aren't just “better 2PC.” You can use consensus to build systems that coordinate decisions reliably, but consensus protocols and commit protocols address different layers of the problem.
A quick comparison
| Pattern | Best fit | Main trade-off |
|---|---|---|
| 2PC | Immediate all-or-nothing consistency | Blocking and coordination cost |
| Saga | Multi-step business workflows | Eventual consistency and compensation complexity |
| Transactional outbox | Reliable event publication | More moving parts in async processing |
| Event sourcing | Auditability and replay | Higher modeling and operational complexity |
The right choice depends on what failure you can tolerate: temporary inconsistency, delayed completion, or blocked progress.
Choosing the Right Transaction Model for Your SaaS
If your workflow cannot tolerate split outcomes, and the participating systems are few, tightly controlled, and relatively stable, Two-Phase Commit Protocol thinking still earns its place. It gives you a strict model for preserving atomicity.
If your workflow spans multiple independent services, external APIs, or user-facing systems where availability matters, an eventually consistent approach is usually more practical. That often means Sagas, compensating actions, outbox patterns, and strong reconciliation processes.
For most B2B eCommerce SaaS teams, the key question isn't “Should we implement 2PC?” It's “Where do we need strict all-or-nothing behavior, and where do we need safe recovery from partial failure?” Those are different design goals.
Use this shortlist:
- Choose 2PC-style coordination when one wrong partial result is unacceptable.
- Choose Saga-style orchestration when business steps can be compensated.
- Choose async integration patterns when throughput, resilience, and external API variability matter more than immediate cross-system consistency.
- Choose an abstraction layer when connector sprawl is becoming the bigger engineering problem than transaction semantics.
A mature architecture usually mixes these models. You might keep strict local transactions inside one service boundary, use compensating workflows across services, and rely on normalized integration infrastructure for third-party commerce connections.
If your team is building eCommerce integrations and wants to ship faster without maintaining separate connectors for dozens of platforms, API2Cart gives you one unified API for orders, products, inventory, shipments, and more across many shopping carts and marketplaces. It's a practical way to reduce connector complexity so your developers can spend more time on product logic and less time rebuilding integration plumbing.



