
Most explanations of what abandoned cart recovery is start with marketing copy. Developers need a different framing. The useful question isn't “how do I remind shoppers?” It's “how do I detect a stalled checkout event across many carts, normalize the data, trigger a follow-up fast enough to matter, and keep that pipeline reliable at scale?”
That matters because cart loss isn't a fringe issue. Baymard's aggregated benchmark puts average cart abandonment at 70.22% across 50 studies, roughly 7 in 10 carts, and notes that the average has stayed around 68% to 70% since 2014 according to this cart abandonment benchmark summary. For a SaaS team building ecommerce automation, that's not just a merchant pain point. It's a stable integration problem with a clear business case.
The Abandoned Cart Problem Is a Developer Opportunity
Developers often inherit abandoned cart recovery as “send an email after someone leaves.” That description hides the actual work. Recovery is an event detection and orchestration problem: identify a drop-off, resolve customer identity, fetch current cart data, decide channel eligibility, then trigger the right message while the shopper still remembers the session.

The size of the opportunity is unusually clear. When roughly 7 in 10 carts are abandoned and the pattern has remained high for years, recovery stops being a nice-to-have and becomes core product infrastructure. If your SaaS already touches order data, customer events, messaging, analytics, or checkout workflows, recovery is one of the most direct ways to make your product useful.
What developers are actually building
At the system level, abandoned cart recovery usually includes:
- Event capture: detect that a shopper added products, entered checkout, or dropped before payment.
- Identity resolution: determine whether you have an email, phone number, device token, or only an anonymous session.
- Payload assembly: collect cart lines, product names, images, prices, links, and checkout URL or restore token.
- Workflow execution: schedule reminders, suppress duplicates, stop messages if the order later completes.
- Measurement: record recovery attempts and attribute completed purchases back to the workflow.
Practical rule: treat recovery as a distributed system, not a campaign template.
That mindset changes design decisions. You stop asking whether a reminder email is “enabled” and start asking whether your connectors deliver fresh cart state, whether retry logic prevents missed events, and whether your platform abstraction leaks at the worst possible moment.
For B2B SaaS, that's a significant opening. Merchants want revenue recovery. Product teams want a feature with obvious ROI. Developers become the team that turns fragmented platform behavior into one reliable service.
The Business Case for Recovery Features in Your SaaS
Recovery features are sticky because merchants can connect them to a simple outcome: fewer stalled transactions. That makes them easier to justify than broad “engagement” tooling. If your product can identify likely lost checkouts and act on them, users see the value in operational terms, not abstract dashboards.

The economics are straightforward. Recovery workflows usually combine reminders with checkout fixes because unexpected costs such as shipping, taxes, and fees are the top abandonment trigger, cited by about 48% of shoppers. Standard email programs often recover 3% to 5% of carts, while stronger programs can reach 10% to 20%, based on the figures compiled in this abandoned cart recovery rates overview.
Why SaaS teams should prioritize it
A recovery feature tends to improve three things at once:
| Stakeholder | Why it matters |
|---|---|
| Merchants | They get a measurable way to win back otherwise lost transactions. |
| Your product team | You add a feature that's easy to position and easy to evaluate. |
| Customer success and sales | They can tie onboarding and renewal conversations to a concrete workflow instead of generic automation claims. |
There's also a roadmap advantage. Recovery sits at the intersection of messaging, analytics, and commerce data. Once you build the connector layer for this use case, the same infrastructure often supports browse abandonment, replenishment reminders, post-purchase flows, and operational alerts.
Build it yourself or buy the integration layer
The hidden cost isn't the email builder. It's the connector estate. Teams underestimate how much engineering time goes into normalizing checkout states, handling auth differences, and tracking platform behavior changes over time. That's why product teams evaluating making build vs buy choices should treat abandoned cart recovery as an integration problem first and a campaign problem second.
A practical way to think about it:
- If your differentiation is workflow logic, keep that in-house.
- If your pain is platform connectivity, abstract it.
- If you need broad cart coverage quickly, avoid bespoke connectors unless that layer is part of your core product strategy.
For teams planning the feature set around messaging and lifecycle automation, API design matters as much as UI. A useful starting point is this overview of ecommerce marketing automation patterns, because it shows how cart-triggered workflows fit into a broader data pipeline instead of living as a one-off email feature.
Recovery Channels and Their Data Requirements
The hard part of recovery isn't choosing channels. It's feeding each channel the right payload, with the right consent state, from the right source of truth. A clean architecture starts by mapping each message type to the minimum data it needs.
Email needs more than an address
Email is still the most forgiving channel because it can carry rich product context. But developers usually need more than customer.email.
A usable abandoned-cart email payload typically includes:
- Customer fields: email, first name, locale, consent status
- Cart fields: cart or checkout ID, currency, subtotal, line items
- Line item fields: product name, variant, quantity, price, image URL, product URL
- Recovery fields: restore-cart link or checkout link, expiration logic, applied incentive if any
If your team is working through payload design, this guide to gathering store data for abandoned cart emails is useful because it keeps the discussion grounded in actual store objects rather than vague automation advice. For the messaging side, a good companion read is this email automation guide, especially for thinking through sequencing and template dependencies.
SMS and push need tighter data discipline
SMS and push look simpler, but they're less forgiving when your data is incomplete or stale.
SMS usually needs:
- phone number
- messaging consent
- short cart summary
- a compact recovery URL
Push usually needs:
- device token or app identity
- notification permission status
- short title/body copy
- deep link back into app or web checkout
Because these channels have less room for explanation, the restore path has to work on the first tap. Broken deep links, expired carts, or outdated prices degrade trust quickly.
Recovery messages fail for technical reasons more often than teams admit. The product image changed, inventory moved, or the restore URL points to a dead cart state.
Retargeting and on-site reminders use different identifiers
Not every shopper is known by email or phone. For those cases, recovery shifts from direct messaging to identity-light tactics such as retargeting or on-site return prompts. That changes both the data model and the orchestration layer.
Here's the practical split:
| Channel | Primary identifier | Typical payload need |
|---|---|---|
| Email address | Rich cart data and restore URL | |
| SMS | Phone number | Consent, short link, concise item summary |
| Push | Device or app user ID | Deep link and compact message |
| On-site return | Session or browser identity | Recently viewed cart state and rehydration logic |
The engineering takeaway is simple. Don't design “abandoned cart recovery” as one workflow with four output options. Design it as a trigger service with channel-specific eligibility rules and payload builders.
The Integration Challenge Webhooks vs Polling APIs
Detection latency decides whether your workflow feels timely or stale. Consequently, architecture starts to affect conversion outcomes directly.
Dotdigital reports that 45% of cart recoveries happen within the first two hours, which is why low-latency detection matters so much, as noted in this abandoned cart recovery strategy article. If your system discovers a cart six hours late because it waited for a batch job, your message can still work, but you've already missed the highest-intent window.
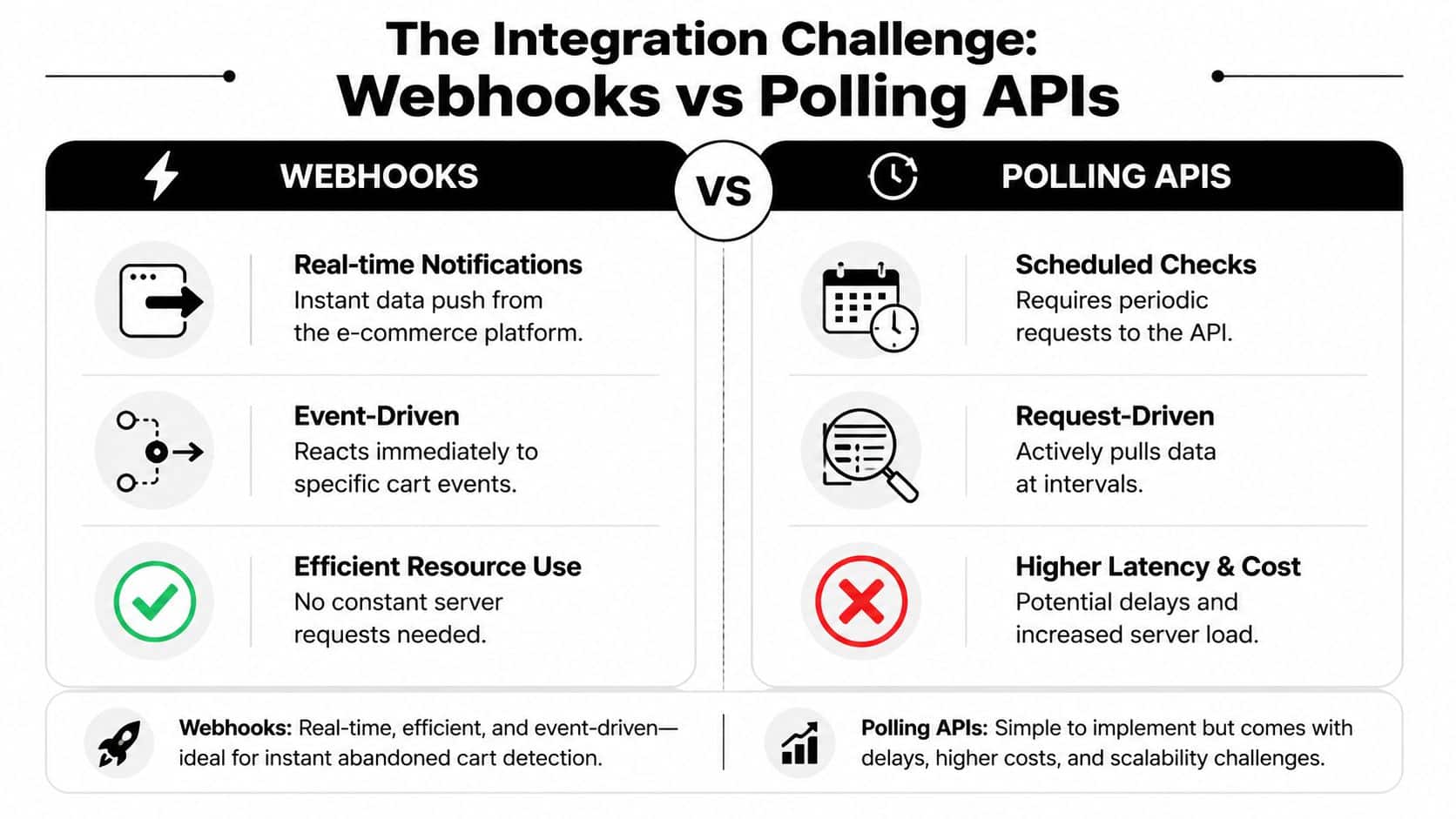
Why webhooks are the cleanest pattern
Webhooks are event-driven. A platform pushes a notification when something important happens, and your system reacts.
That gives you three immediate benefits:
- Lower latency: messages can trigger close to the abandonment event.
- Lower waste: you don't keep asking the platform for data that hasn't changed.
- Better orchestration: queues, retries, and downstream consumers can process an event stream cleanly.
For recovery, that usually means your application receives a checkout-related event, enriches it with cart data, writes state to a workflow engine, then schedules channel actions.
But webhooks aren't automatically simple. Real implementations have to deal with:
- missing event types on some carts
- delivery retries and duplicate events
- signature verification and replay protection
- ordering issues when update and completion events arrive close together
Why polling still matters
Polling is less elegant, but it's often the practical fallback. Many platforms don't expose the exact event you want, or they expose it inconsistently. In those cases, a scheduled fetch of carts or checkouts updated since a timestamp is what keeps coverage broad.
Polling works when you build it carefully:
| Concern | Webhooks | Polling |
|---|---|---|
| Latency | Usually lower | Depends on interval |
| Coverage | Depends on platform support | Usually broader |
| Infrastructure load | Event-driven | Repeated requests |
| Failure mode | Missed deliveries | Delayed discovery |
| Implementation burden | Queueing and verification | Scheduling, dedupe, rate handling |
The mistake is treating polling as a crude backup. Good polling systems track high-water marks, support idempotent reprocessing, and suppress duplicate workflow entry when a later poll finds a cart that was already handled.
Architecture call: use webhooks where the platform emits reliable checkout events. Use polling where event support is partial or absent. Build one deduplication layer that can accept both.
For teams comparing these patterns across store connectors, this discussion of webhooks vs APIs is useful because it frames the decision around operational behavior rather than ideology. In practice, mature recovery systems use both.
Building a Scalable Connector Architecture with API2Cart
Multi-platform recovery breaks when each connector has its own rules for auth, object names, event support, and cart state definitions. Developers feel that pain first. Product teams usually see it later, when releases slow down and maintenance work starts dominating roadmap time.
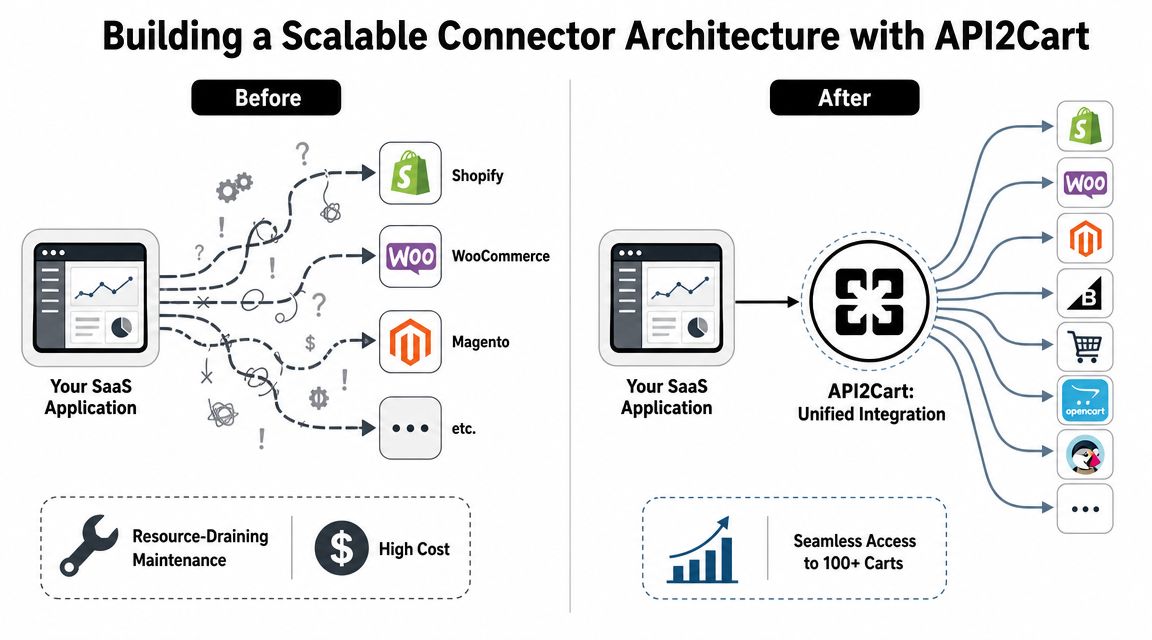
Why direct connectors become a maintenance trap
A single abandoned-cart feature sounds manageable when you're thinking about one platform. Then reality arrives:
- one cart exposes checkouts, another exposes orders in a pending state
- one supports near-real-time notifications, another needs scheduled retrieval
- one returns customer contact data early, another only after a later checkout step
- one platform update changes field behavior and breaks your mapper unnoticed
The engineering burden isn't just writing connectors. It's keeping them alive.
A scalable design usually needs:
- Connector abstraction so your workflow engine doesn't care which cart produced the event.
- Canonical object model for carts, customers, addresses, and line items.
- Capability flags so your system knows whether a store supports webhook delivery, restore links, discounts, or checkout mutation.
- Fallback paths when a store can't support your preferred trigger pattern.
What a unified API changes
A unified integration layer can simplify architecture. Instead of building separate connectors for every platform, your application integrates once and works against one API surface. API2Cart is one example of that model. It provides a single API for many ecommerce platforms, supports both webhook-based sync where available and list methods for polling, and exposes methods such as order.abandoned.list for incomplete orders used in recovery workflows.
That changes the shape of the application. Your team can keep the logic that matters:
- event ingestion
- segmentation rules
- message sequencing
- attribution
- observability
And push connector-specific differences down into the integration layer.
A practical target architecture
A solid recovery stack built on a unified API generally looks like this:
| Layer | Responsibility |
|---|---|
| Store connection layer | Auth, platform compatibility, normalized access |
| Detection layer | Webhook intake, polling jobs, deduplication |
| Canonical data model | Normalized cart, customer, product, and checkout objects |
| Workflow engine | Delay rules, channel branching, suppression logic |
| Analytics layer | Recovery status, completed purchase attribution, operational logs |
This pattern speeds delivery because developers stop rewriting adapter code for each new platform. It also improves reliability. When one connector changes, you don't want the abandoned cart workflow team rewriting business logic. You want a stable contract and a clear place where translation happens.
The biggest gain from a unified API isn't convenience. It's containment. Platform volatility stays in one layer instead of leaking through your entire product.
Advanced Strategies and Critical Pitfalls to Avoid
Basic recovery is easy to launch and easy to overestimate. The systems that hold up in production usually do less guessing and more qualification.
Don't confuse cart abandonment with checkout abandonment
This is the mistake that breaks roadmap promises. Developers, marketers, and even product docs often talk about abandoned carts as if every shopper who added an item can be recovered. That isn't operationally true on every platform.
Shopify's documentation is clear that recovery applies to abandoned checkouts where the customer has provided an email, which means anonymous carts can't be recovered in the same way, as explained in Shopify's abandoned checkout documentation. If your architecture doesn't account for that distinction, your feature spec will promise visibility the platform never exposes.
A better model is to separate users into buckets:
- Known checkout abandoners who can receive direct recovery messages
- Known browsers who may qualify for other lifecycle flows
- Anonymous sessions who can only be handled through identity-light tactics until they identify themselves
Be careful with discounts
Discounts can lift response, but they also create product and margin risk. If every final reminder contains a coupon, shoppers learn the pattern. Some of them will wait.
What works better in many implementations is progressive intervention:
- first message as a plain reminder
- second message answers objections or surfaces reassurance
- only later, and only for selected segments, test an incentive
That keeps recovery from turning into discount training. It also gives your analytics a cleaner view of whether the friction was price, timing, or trust.
Reliability issues usually hide in the edges
The failures that hurt most aren't dramatic outages. They're quiet mismatches:
- a cart updates after the message was queued
- inventory changes between detection and send time
- a shopper completes purchase in another tab but still receives the reminder
- email gets accepted by the provider but lands poorly because sending reputation is weak
If your team handles email delivery in-house, operational discipline matters as much as template design. This guide on how to stop email from going to spam in Gmail is a useful operational reference because recovery emails only work when they land in front of the shopper.
Build suppression and state revalidation into every send step. Right before a message goes out, confirm that the checkout is still abandoned and that the cart data is still valid.
The same principle applies to multi-channel sequences. Email plus SMS can work well, but only if the system reevaluates eligibility before each touch. The more channels you add, the more important idempotency, consent tracking, and fresh cart state become.
Developer FAQ for Abandoned Cart Integration
How do you recover carts on platforms that don't support native abandoned-cart webhooks?
Use polling as a fallback. Fetch recently updated carts or incomplete orders on a schedule, compare against your stored state, and push only newly qualified records into the workflow. The key is deduplication and timestamp tracking.
What should the normalized payload include?
At minimum: store identifier, cart or checkout identifier, customer identity fields if available, line items, prices, currency, restore or checkout URL, consent status, and last-updated timestamp. Add source-platform metadata separately so your business logic can stay platform-agnostic.
Should recovery logic live in the connector layer?
No. The connector layer should retrieve and normalize data. Trigger timing, segmentation, channel choice, suppression rules, and attribution belong in your application layer.
Can the system apply incentives automatically?
Sometimes, but capability varies by platform and by how the cart or checkout object is exposed. Design incentives as optional workflow actions behind capability checks, not as guaranteed behavior.
If you're building abandoned cart recovery into a B2B ecommerce product, API2Cart is worth evaluating as the integration layer. It gives developers one API for many ecommerce platforms, supports webhook and polling patterns, and helps teams ship recovery workflows without maintaining a large connector estate themselves.



