
A lot of integrations look solid in staging and then fail in production for one boring reason: pagination in api wasn't treated as a first-class problem.
The first sync runs fine against a store with a small catalog. Then a larger merchant connects. Orders keep arriving while your importer is still paging through yesterday's data. Inventory changes mid-run. One endpoint returns page and limit, another returns a token, and a third caps page size without notification. The result isn't just slower syncs. It's duplicate orders, skipped products, retries that restart from the wrong place, and support tickets that are hard to reproduce.
For integration developers, pagination is not UI sugar. It's data movement control. If you build OMS, WMS, PIM, ERP, shipping, analytics, or marketing integrations, your sync quality depends on whether your paging logic survives unstable datasets, inconsistent vendor conventions, and rate limits.
Why API Pagination Can Break Your eCommerce Integration
A fragile integration usually doesn't fail on record one. It fails on record 40,001.
Your code requests products in batches, stores them, advances to the next page, and keeps going. In test data, that seems harmless. In a live commerce environment, it's risky. New orders appear while you paginate. Stock updates reorder results. Some APIs delete canceled records from list responses. If your loop assumes the dataset stays still, your sync drifts without telling you.

What breaks in the real world
The common failure pattern looks like this:
- A page shifts during sync because a new record lands at the top of the result set.
- The client retries blindly after a timeout and reprocesses records from the previous page.
- The endpoint slows down deep in the dataset and starts hitting worker time limits.
- A connector resumes from the wrong position after a crash because it only stored a page number, not a stable checkpoint.
These aren't edge cases. They're normal conditions in active stores.
Practical rule: If an endpoint returns changing business data such as orders, inventory, or prices, assume the dataset is moving while you read it.
Why developers underestimate it
Pagination feels mechanical, so teams often push it to the end of implementation. They focus on authentication, field mapping, and webhook delivery first. Then they add a simple loop and call it done.
That's backwards. In eCommerce, pagination defines whether your sync can be trusted. A clean mapping layer won't save you if your importer skips records under load. A webhook strategy won't save you if you still need backfills, historical imports, and reconciliation jobs.
When people search for guidance on pagination in api, they usually find basic examples. What they need is operational guidance: how to keep pagination reliable when data changes between requests, when vendors paginate differently, and when retries happen mid-stream.
Core API Pagination Strategies Explained
Most APIs use one of a few pagination patterns. The mechanics matter because your client has to follow the server's rules exactly, not the way you wish the endpoint worked.
If you need a quick refresher on the API style most of these list endpoints follow, this overview of Representational State Transfer gives the right baseline for how resource-oriented HTTP APIs are typically structured.
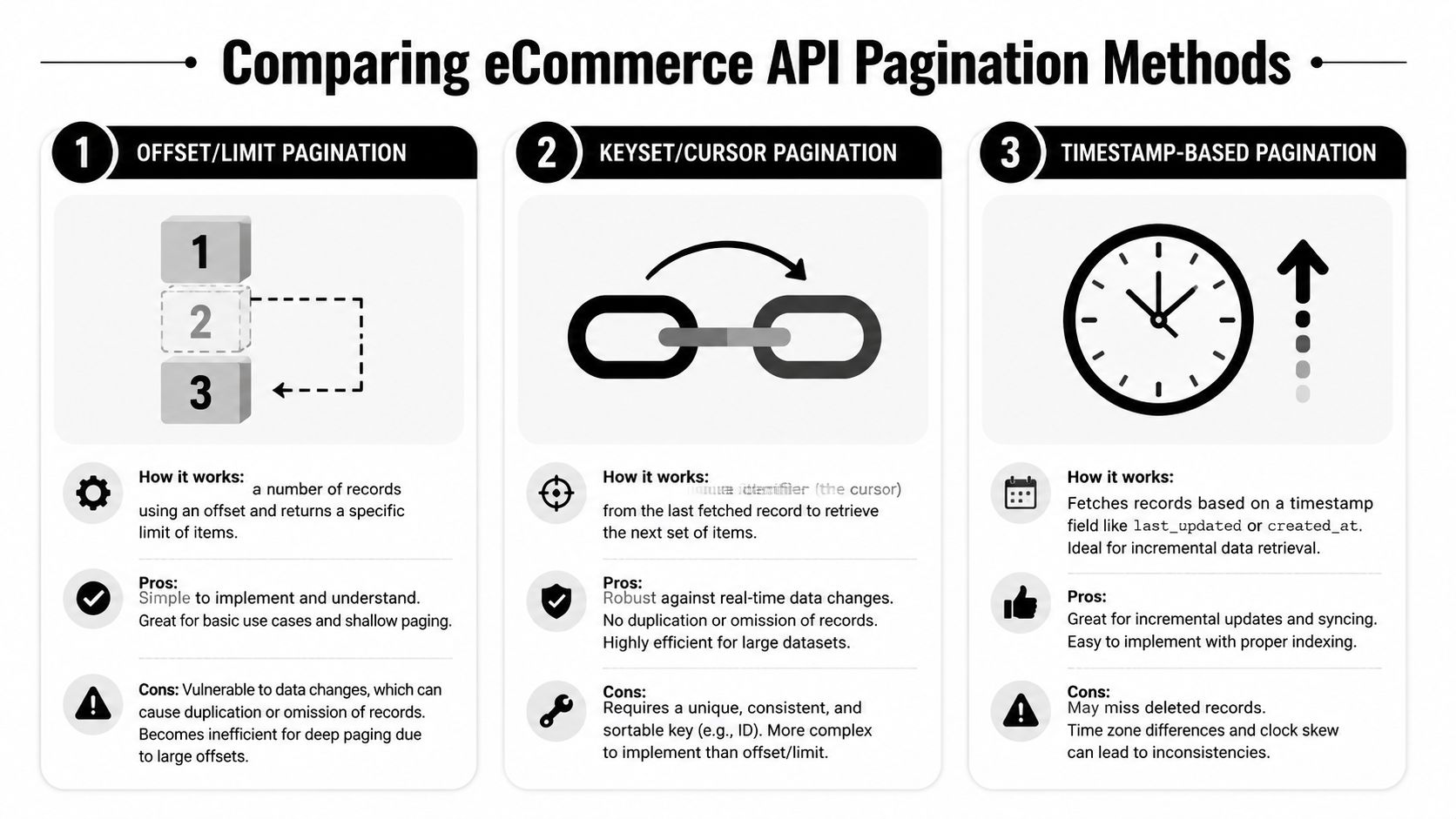
Offset and limit
Offset pagination is the oldest and easiest to understand. You ask the API to skip a number of records and return the next batch.
Typical request pattern:
?offset=0&limit=100?offset=100&limit=100?page=3&limit=100
It behaves like flipping to a numbered page in a book. The problem is that the server still has to move through the earlier rows before it gives you the current batch. According to this pagination analysis, offset-based pagination was used by the original Twitter API in 2006, but high offsets could take 10 to 100x longer, which helped push major platforms toward cursor methods. The same source notes that some platforms reduced query times by up to 50% after making that shift.
Offset is still common because it's simple for developers and easy for admin-style UIs that want page numbers.
It works best when:
- The dataset is relatively small
- The sort order is stable
- Users need direct page jumps
- The data doesn't change much during reads
It works badly for busy order feeds and large catalogs.
Cursor pagination
Cursor pagination replaces page numbers with a position marker. Instead of asking for “page 5,” the client asks for the next records after a known item.
Typical request pattern:
?after=opaque_cursor_value&limit=100
Typical response fields:
has_morenext_cursor
Think of it as a bookmark, not a page number. The server gives you a token that represents where to continue. Good cursor systems sort by a stable field and use a deterministic tie-breaker so each next request continues exactly where the previous one ended.
This is the right fit when data changes frequently. New records can appear, but the cursor still points to a stable continuation point.
Page tokens and server-issued continuation markers
Some APIs don't expose a visible cursor model at all. They return a next-page token or continuation token that you pass back exactly as received.
Typical response shape:
next_page_tokennextcontinuation
This is functionally close to cursor pagination. The difference is conceptual. With a token-based model, the server owns the paging state and tells you what to send next. You don't inspect it, derive from it, or reconstruct it.
What matters more than the label
The name of the strategy matters less than these implementation details:
- Stable sort order: You need to know what field controls progression.
- Deterministic continuation: Two requests shouldn't overlap unless you're intentionally replaying.
- Clear termination: The API should tell you when there are no more pages.
- Recoverability: Your client should be able to resume from the last successful checkpoint.
If the API gives you an opaque token, treat it as write-only data. Store it, resend it, and don't build logic that depends on decoding it.
Comparing Pagination Methods for eCommerce Data Syncs
The right pagination method for a storefront search screen is not always the right method for order imports. eCommerce syncs are harder because the data changes while you read it.
Offset pagination breaks most often when records are inserted or removed between requests. A new order can push everything down by one position. Your next offset=100 request may now include one item you already processed and miss one item you haven't. That's the page-shift problem.
Cursor and keyset approaches handle that better because they continue from a stable record boundary instead of a moving row count. According to this implementation guide, cursor-based methods can reduce latency by 80 to 90% for pages beyond 10,000 items compared with offset methods.
Pagination Strategy Comparison Offset vs. Cursor
| Feature | Offset/Limit Pagination | Cursor-based Pagination |
|---|---|---|
| How it moves forward | Skips a counted number of rows | Continues after a server-defined position |
| Performance deep in large datasets | Degrades as the offset grows | Stays stable when implemented on indexed fields |
| Behavior during inserts and deletes | Can skip or duplicate records | Much more reliable for forward-only syncs |
| Supports direct page numbers | Yes | Usually no |
| Best fit | Small, mostly static datasets | Large, active datasets such as orders and inventory |
| Client complexity | Lower at first | Higher, but more durable |
| Operational risk in eCommerce | High for live syncs | Lower when sort order is stable |
Why timestamp filters matter too
A third pattern shows up often in integrations: timestamp-based pagination. Instead of traversing the entire collection, the client requests records updated after a checkpoint such as updated_at_min.
That doesn't replace proper pagination. It narrows the result set first, then pagination carries the rest. For polling jobs, this is often the most efficient pattern because you aren't rereading old records on every cycle.
Use timestamp filtering when you need:
- Incremental syncs after an initial import
- Short polling windows for new orders or modified products
- Reconciliation jobs that only inspect recent changes
The practical choice for sync pipelines
For admin UIs, offset is often acceptable. For data pipelines, it usually isn't. If your integration is importing changing business records, choose deterministic forward progress over user-friendly page numbers.
If you want a concrete example of how a unified connector layer exposes this model, API2Cart has a note on support for cursor-based pagination in list methods.
The moment your sync logic depends on “page 7 still means the same thing five seconds later,” you're building on a false assumption.
The Inconsistent World of eCommerce API Pagination
Understanding pagination patterns is the easy part. Living with dozens of incompatible implementations is the hard part.
A single integration team may connect to carts, marketplaces, and order sources that all paginate differently. One endpoint uses cursors. Another expects start and count. Another returns a continuation token with no indication of how long it remains valid. Some vendors include total counts. Some don't. Some sort newest first. Others sort oldest first unless you add an explicit parameter.

The cost isn't just code volume
The interoperability gap is the hidden tax. As noted in this analysis of web API pagination types, B2B integration platforms that connect to 70+ carts and marketplaces deal with a mix of cursor, offset, and vendor-specific models, each with different rate limits and failure modes.
That means your team has to maintain far more than a loop.
You also need to handle:
- Different parameter names for the same idea
- Different page-size caps across connectors
- Different retry behavior when a paginated request hits rate limiting
- Different error semantics when a token expires or a page becomes invalid
- Different sorting defaults that affect duplicate detection and resume logic
Why this creates brittle integrations
The first version usually starts with adapter-specific branching:
- If connector A, use
page_info - If connector B, use
offset - If connector C, pass back
nextToken - If connector D, poll by date and then paginate locally
That logic spreads. It enters the importer, the retry code, the scheduler, and the reconciliation jobs. Then one vendor changes an endpoint, and your generic sync worker stops being generic.
A pagination bug rarely stays isolated. It leaks into checkpoint storage, retry design, throughput planning, and customer support.
For developers building multi-platform SaaS products, pagination inconsistency isn't a small nuisance. It's part of the architecture. If you ignore that early, you end up with connector-specific behavior all over the codebase.
Robust Pagination Implementation Patterns and Best Practices
You can't force external APIs to paginate well. You can make your client resilient.
A strong pagination client has one job: move forward exactly once, even when requests fail, data changes, or rate limits interrupt the loop.
Store checkpoints like durable state
Treat the last successful pagination position as durable application state.
That means persisting:
- The continuation marker such as cursor, token, or last seen key
- The sync boundary such as the time window you're processing
- The sort assumptions if the connector allows configurable sorting
Never keep this only in memory. If a worker restarts, you want to resume from the last confirmed position, not from the beginning and not from a guessed page number.
A practical checkpoint record often contains:
| Field | Purpose |
|---|---|
| integration_id | Identifies the connected store |
| resource_type | Orders, products, customers, inventory |
| cursor_or_token | Next continuation value |
| window_start | Lower bound of the sync range |
| last_success_at | Audit and recovery reference |
Combine pagination with change windows
For frequently updated resources, a full collection walk on every cycle is wasteful. Poll by change window first, then paginate inside that narrowed result set.
A common pattern looks like this:
- Read the last committed sync timestamp.
- Request records updated after that timestamp.
- Process pages until no more remain.
- Commit a new high-water mark only after the run succeeds.
This reduces load and limits replay scope when something fails.
Operator advice: Advance your checkpoint after durable processing, not after the HTTP response arrives.
Handle rate limits and transient failures without losing position
Rate limiting and 5xx responses are normal, not exceptional. Your client should retry without corrupting progress.
Use these rules:
- On 429 responses: back off, wait, and retry the same request with the same continuation marker.
- On transient 5xx errors: retry with capped attempts and jittered delay.
- On invalid or stale cursor errors: restart from the last committed safe boundary, not from the middle of partially processed data.
- On partial processing failures: avoid moving the checkpoint until downstream writes succeed.
Prefer deterministic keysets when you control the API
If you're designing your own endpoint or federation layer, keyset pagination is usually the right base for large datasets. According to this implementation reference, keyset pagination can achieve sub-millisecond seeks by using indexed key comparisons such as WHERE (created_at, id) > (last_seen_at, last_seen_id). The same guidance recommends page sizes in the 50-200 range, server-side cursor validation, and HATEOAS links. It also notes these practices can reduce client-side errors by up to 70%.
A durable server response for pagination in api should include enough metadata for safe continuation:
has_moreso the client knows when to stop- A next cursor or next link so the client doesn't construct pagination state incorrectly
- Stable ordering on indexed fields with a tie-breaker
- Reasonable page size caps to avoid abuse and unpredictable latency
Pseudocode for a resilient sync loop
load checkpoint
set sync_window_start from checkpoint
do
response = fetch page using checkpoint cursor and sync_window_start
process records idempotently
save next cursor only after processing succeeds
if response.has_more is false, exit loop
while true
commit new sync timestamp
The important detail isn't the syntax. It's the order of operations. Fetch, process, then persist progress. Not the other way around.
How API2Cart Solves the API Pagination Challenge
Many teams don't struggle because they don't understand cursor versus offset. They struggle because they have to support many pagination models at once.
That's where a unified integration layer changes the work. Instead of exposing each cart or marketplace exactly as-is, the platform translates those differences into a more consistent contract for the client.

What gets abstracted away
With a unified API approach, an integration developer doesn't need separate pagination handlers for every connector. The client works against a normalized layer for common commerce resources such as orders, products, customers, shipments, and inventory.
In practice, that helps in a few specific ways:
- One pagination contract for list methods instead of connector-specific request patterns
- Less branching in sync workers because the connector translation happens below your application layer
- Cleaner retry logic since you're handling a normalized API surface, not dozens of vendor-specific response shapes
- Faster onboarding of new commerce platforms because the app integrates to one interface, not to each platform independently
Why that matters for integration teams
This is less about convenience and more about architecture control. When your application code talks to a unified layer, your OMS, WMS, PIM, ERP, or analytics product can standardize how it stores checkpoints, schedules imports, and resumes after failure.
That doesn't remove the need to understand pagination in api. It changes where the complexity lives. Instead of hard-coding pagination edge cases throughout your product, you centralize them behind a connector abstraction.
For teams building multi-store syncs, order ingestion, catalog imports, or inventory updates across many commerce systems, that's often the difference between shipping features and maintaining connector-specific plumbing forever.
Building Scalable Integrations with Smart Pagination
Good pagination isn't a minor implementation detail. It's part of data correctness.
Offset, cursor, keyset, and token-based models all have valid use cases. A significant issue for integration developers is that eCommerce systems rarely agree on one model, one parameter set, or one failure pattern. That's why scalable sync architecture needs both sound pagination logic and a deliberate abstraction strategy.
If your team is building data-heavy commerce workflows, this practical overview from DataEngineeringCompanies.com's page is a useful companion read because it frames the broader pipeline concerns around eCommerce data movement. On the API side, rate limiting is tightly connected to paging behavior, so it also helps to understand API rate limit handling as part of the same operational design.
The teams that scale cleanly don't just write a loop that fetches the next page. They store checkpoints, process idempotently, narrow sync windows, and avoid letting connector-specific pagination rules spread through the whole product.
If your product needs to connect with many commerce platforms without building separate pagination and sync logic for each one, API2Cart gives you a unified integration layer for orders, products, customers, inventory, and other store data. It's a practical way to reduce connector-specific code, speed up integration delivery, and keep your team focused on product workflows instead of pagination edge cases.



