
A lot of integration teams still treat third party aggregators as a business-side topic. They aren't. They're an engineering topic, and often a painful one.
That matters because the category is no longer niche. The global payment aggregator market was valued at about 5.3 billion U.S. dollars in 2023 and is projected to reach 13.8 billion U.S. dollars by 2032, with an 11.2% CAGR, according to payment aggregator market data. That growth reflects something developers already feel in day-to-day work. Companies keep outsourcing complexity into unified layers because maintaining direct integrations across fragmented systems gets expensive fast.
If you're building a SaaS product for merchants, operators, or marketplace sellers, you don't just need connectivity. You need connectivity that survives API changes, auth changes, schema drift, partial failures, and ugly edge cases in real production traffic. That's where the aggregator model becomes practical architecture, not just market jargon.
The broader API economy business model in eCommerce exists for one reason: software teams need a repeatable way to plug into many systems without rebuilding the same connector logic over and over.
The Rise of the Aggregator Economy
Third party aggregators became important because platform fragmentation kept growing while merchant expectations got simpler. Merchants want one workflow. Developers inherit twenty different ones.
In eCommerce, that gap shows up everywhere. One platform calls it a product variant, another treats it as an option combination. One marketplace sends fulfillment events in near real time, another expects polling. One cart gives you clean order status values, another gives you a custom status that means three different operational states depending on merchant configuration.
Why developers should care
For an integration developer, an aggregator is usually a response to one hard constraint: your roadmap can't support a separate engineering track for every platform your customers use.
You can feel that pressure in common SaaS categories:
- Order management tools need consistent order ingestion across many storefronts.
- Inventory systems need stock updates to flow back without double-decrement errors.
- Shipping apps need a stable order and shipment model before label logic even starts.
- Analytics and automation products need customer, cart, and product data in a normalized shape.
Practical rule: The moment your product value depends on supporting more than a small number of commerce platforms, integration architecture becomes part of product strategy.
Why the model keeps spreading
The rise of aggregators isn't only about convenience. It's about ownership of repetitive engineering work. Someone has to manage authentication, schema translation, platform version drift, and support tickets caused by external API behavior. You can own that burden in-house, or you can move a large share of it into a unified layer.
This explains why third party aggregators continue to emerge throughout payments, banking, shipping, and eCommerce infrastructure. They bundle complexity into a reusable service boundary. For developers, the fundamental question isn't whether the model exists. It's whether your team should build that boundary itself or consume one.
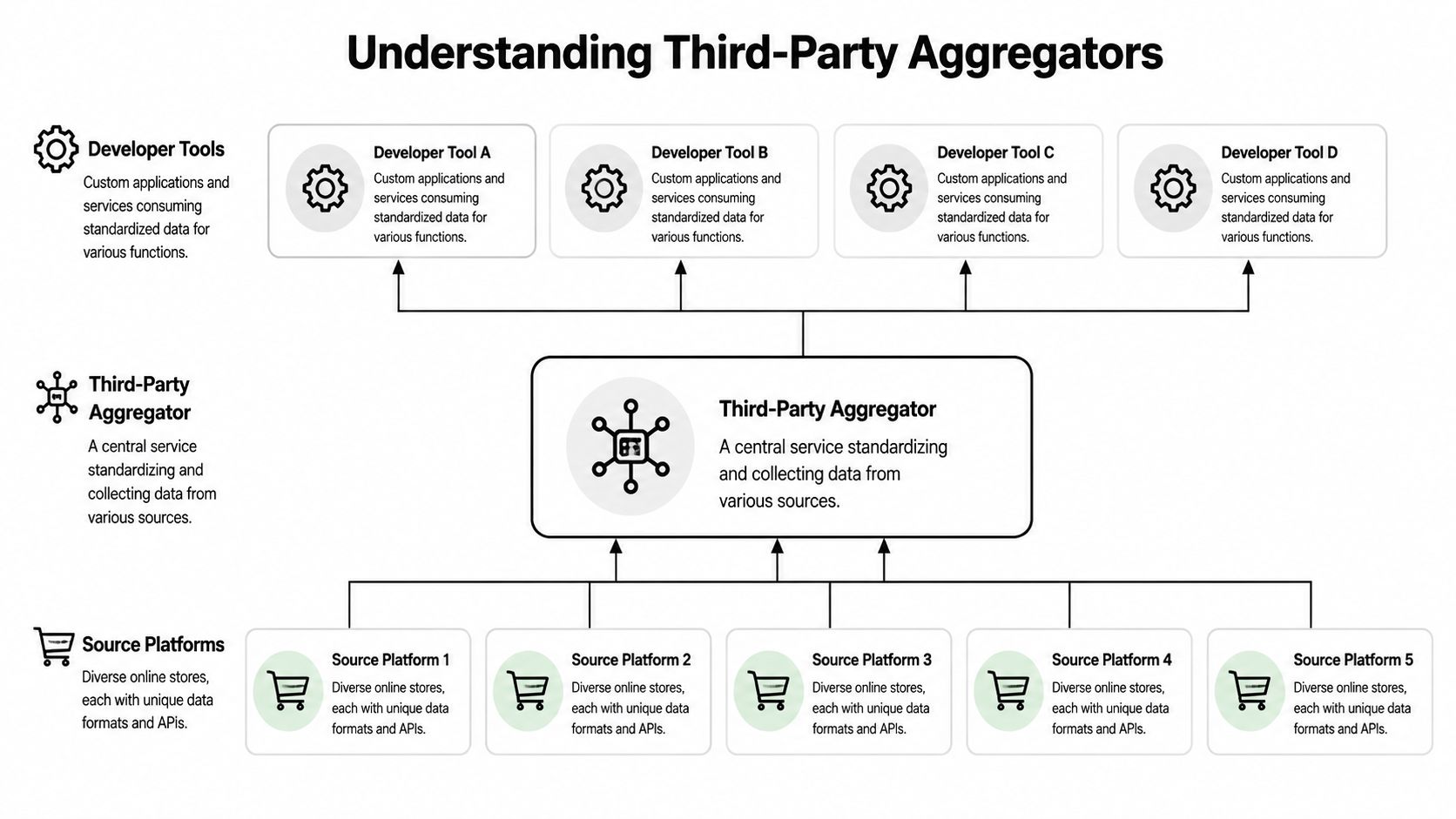
What Are Third Party Aggregators
A third party aggregator is a middle layer that sits between many source systems and the application consuming their data. It collects, standardizes, and exposes access through a more consistent interface.
In plain terms, it turns "connect to many different APIs" into "connect to one service that already knows how to talk to many APIs."
If you want a broader framing of the category, this overview of API integration services and how they work is useful background. For implementation work, though, the distinctions between aggregator types matter more than the label.
Marketplace aggregators
In one branch of the market, aggregators aren't technical connectors at all. They're operators that acquire and scale third-party seller businesses. Amazon aggregators are the clearest example.
That segment had a dramatic cycle. Funding to Amazon aggregators peaked at 6.17 billion U.S. dollars in 2021, more than 100 aggregators had entered the market by late 2021, and Amazon third-party sellers represent over 60% of sales on the marketplace, according to Statista's overview of Amazon aggregators. For developers, the takeaway isn't investor history. It's that aggregator models can create huge advantages, but they also concentrate operational complexity.
Operational aggregators
The type most integration developers deal with is the operational aggregator. This category usually does one or more of these jobs:
- Normalize commerce data so orders, products, customers, shipments, and inventory can be handled through a common model.
- Broker authentication so your app doesn't have to implement separate platform-specific connection flows.
- Absorb platform churn when upstream APIs change behavior, payloads, or permission rules.
Third party aggregators function as architectural infrastructure rather than just business entities.
Payment and shipping style aggregation
Another common pattern is transactional aggregation. A single service acts as the central interface for payment processing, shipping requests, or other operational tasks that would otherwise require many separate integrations.
The useful developer analogy is simple. Instead of writing custom code for each external system, you code against a hub. The hub still has to deal with all the messy differences underneath. Your application gets a cleaner contract.
The abstraction helps only if the aggregator's model is stable, well-documented, and honest about what can't be normalized cleanly.
Bad aggregators hide source-specific behavior until it breaks production. Good ones expose a common model and preserve source-specific escape hatches where they matter.
The Role of Aggregators in Modern eCommerce
Merchants adopt aggregators because selling across channels creates operational coupling. Inventory, fulfillment, customer service, and reporting all depend on data arriving in the right system at the right time.
A merchant may list products on a storefront, a marketplace, and additional sales channels while using separate systems for shipping, stock control, and post-purchase messaging. Without some kind of aggregation layer, they end up copying data between systems or tolerating lag and inconsistency.
What merchants actually need
The merchant use case usually isn't "I want an aggregator." It's one of these:
- Keep stock aligned so a sale on one channel doesn't create oversells elsewhere.
- Pull orders into one backend for fulfillment, support, and accounting workflows.
- Push catalog changes broadly without updating each storefront manually.
- Track customer and shipment events in one place for downstream automation.
When your SaaS integrates with merchants, you inherit these expectations. If your product claims multi-channel support, users expect a workflow that feels unified even when the underlying platforms aren't.
A lot of marketplace integration work exists because merchants don't think in platform boundaries. They think in business processes. That's why marketplace integration for commerce systems matters to product teams. It aligns software architecture with how sellers operate.
Why this changes product requirements
From the SaaS side, that means your integration layer isn't a side feature. It defines onboarding speed, support burden, and how quickly customers can expand into additional channels.
When teams miss this, they often ship a narrow direct connector that works for one platform and then struggle once customers request broader coverage. The merchant sees one feature request. The engineering team sees a new auth flow, a different order schema, another webhook format, and another support matrix to own.
Merchant demand for unified operations is what turns third party aggregators from "nice to have" into infrastructure.
The Core Integration Challenge for Developers
The hardest part of supporting third party aggregators isn't making the first API call. It's building software that keeps working after the easy demo.

Every direct integration starts with optimism. You map a few endpoints, store some tokens, sync orders, and call it done. Then production traffic exposes the actual work: retries, pagination inconsistencies, timestamp mismatches, intermittent throttling, missing fields, and source systems that don't behave exactly like their docs suggest.
One of the most underestimated costs in multi-platform development is constant reformatting. In adjacent industries, researchers describe aggregators as adding value through "data reformatting" and "mitigating risk of misinterpreting data" because APIs aren't standardized, as noted in the Kansas City Fed's discussion of data aggregators in open banking.
That description fits eCommerce integration work exactly.
An "order" isn't one thing across platforms. Neither is a refund, fulfillment, tax line, or product image set. If your app needs one canonical internal object, somebody has to build and maintain that mapping logic.
Where direct integrations usually break
The common failure points aren't glamorous, but they consume most of the maintenance budget:
- Authentication drift. OAuth scopes change, token refresh behavior changes, app approval flows change.
- Rate limits and backoff rules. Some platforms tolerate burst traffic, others punish it quickly.
- Schema mismatches. Fields exist in one system and not another, or they exist with different semantics.
- Event reliability. Webhooks can arrive late, duplicated, out of order, or not at all.
- Incremental sync logic. Date filters often miss updates if you don't handle timezone and update-window edge cases carefully.
Here's the practical mistake I see most often in custom builds. Teams optimize for endpoint coverage before they design failure handling. That gives them a broad integration that becomes fragile under load.
What reliable code looks like
A maintainable connector layer usually needs:
- A canonical model for orders, products, customers, shipments, and inventory.
- Source-specific adapters that translate to and from that model.
- Idempotent sync operations so duplicate events don't corrupt state.
- Retry policy by failure class, not one generic retry loop for everything.
- Observability around per-connector latency, error rates, token failures, and data mismatches.
If you don't model partial failure explicitly, the source platforms will do it for you in production.
That is the engineering case for third party aggregators. Not "fewer integrations" in theory. Less repetitive connector maintenance in practice.
Architecting a Scalable Integration Strategy
There are two workable patterns for most SaaS teams. Build the integration layer yourself, or use a unified API layer that already abstracts the connectors.
Both can work. The right choice depends on whether integration plumbing is part of your core product differentiation or just a prerequisite to deliver your actual value.
The in-house pattern
If you build internally, treat integrations as a platform inside your product, not a pile of endpoint wrappers.
A solid in-house approach usually includes an adapter layer, a canonical domain model, source-specific capability flags, and a sync engine that can support both polling and event-driven updates. Teams that skip those abstractions often end up with connector logic leaking into business code, which becomes painful when the fifth or sixth platform arrives.
For teams designing that foundation, this practical guide to system design is useful because it frames the architectural decisions before code hardens around the wrong assumptions.
The unified layer pattern
The second pattern is hub-and-spoke. Your application talks to a single integration boundary. That boundary handles auth, schema translation, connector upkeep, and source-specific quirks.
In similar aggregation-heavy industries, this approach can materially improve responsiveness. The median data-return latency can drop from 8 to 12 seconds per source to roughly 2 to 3 seconds end to end because the aggregator handles persistent connections, schema mapping, and parallel orchestration, according to the BIS paper on account aggregator models. The exact implementation differs in eCommerce, but the architectural lesson is the same: centralized connection management can remove repeated overhead from every downstream integration.
Integration Strategy Comparison
| Factor | In-House Build | Unified API (e.g., API2Cart) |
|---|---|---|
| Initial setup | More control, but you must design data models, auth flows, and connector patterns yourself | Faster path if the needed platforms and objects are already supported |
| Maintenance load | Your team owns API changes, versioning issues, and auth breakage | Much of the connector maintenance shifts into the unified layer |
| Platform expansion | Each new connector is a mini-project | New platforms are added through the same integration contract |
| Data model control | Maximum flexibility, but also maximum mapping effort | Shared schema reduces work, but may require source-specific extensions |
| Operational risk | Fewer third-party dependencies, more internal burden | Dependency on the aggregator's uptime, roadmap, and abstraction quality |
The trade-off that matters
This decision isn't really about build versus buy in the abstract. It's about where you want complexity to live.
If your product wins because of proprietary commerce connectivity, owning the layer can make sense. If your product wins because of planning, automation, optimization, or workflow logic, then spending your senior engineers on connector maintenance is often the wrong use of talent.
How a Unified API Layer Accelerates Development
Teams that support multiple commerce platforms usually spend more engineering time on connector behavior than on product features. A unified API layer reduces that drag by giving the application one integration contract for the common path, even when the upstream systems all behave differently.

From a developer's perspective, the speed gain is not abstract. It shows up in fewer code paths to maintain.
Instead of building separate auth handling, order ingestion rules, retry logic, and webhook parsers for every cart or marketplace, the team writes those systems once against a shared model. That changes the shape of the work. Engineers spend less time chasing platform-specific token issues and payload differences, and more time building the parts customers notice.
What acceleration looks like in code
A unified layer usually improves delivery speed in four places:
- Authentication handling becomes more predictable because the app integrates with one connection pattern instead of many source-specific flows.
- Data mapping gets narrower because orders, products, customers, shipments, and inventory arrive in a normalized schema for the majority case.
- Sync jobs are easier to reuse because polling, deduplication, and webhook consumers can target one payload structure.
- Error handling becomes easier to standardize because upstream failures are often translated into a smaller set of response types your code can classify and retry.
The main benefit is consistency. Consistency reduces branching in the codebase.
A practical example helps. Say you're building order management software and need to support several commerce platforms. Without a unified layer, each connector usually requires its own merchant auth flow, token refresh rules, historical import process, incremental sync logic, shipment update behavior, status mapping, and support playbook when the upstream API changes. That is a lot of repeated engineering.
With a unified layer, much of that effort moves behind the integration boundary. API2Cart is one example. It provides a single eCommerce API for connecting to many shopping carts and marketplaces through one interface. For the application team, that means one path to import orders, sync inventory, update catalog data, retrieve customer records, and combine webhooks with polling for recovery when events are delayed or missed.
That does not remove the hard parts. It contains them.
Where developers still need to do real work
Normalized APIs speed up delivery, but they do not erase source differences. Some platforms expose richer order states. Some have stricter rate limits. Some support write operations for shipments or inventory in one way, and others only partially support them. Those gaps still affect application logic.
Good implementations account for that explicitly:
- Keep a shared internal model for the common workflow.
- Store source-specific metadata when the normalized fields are not enough.
- Add capability flags so the UI and job runners know which actions are supported per connection.
- Build retry rules around error categories such as auth expiry, throttling, validation failures, and temporary upstream outages.
This is also where staffing matters. If the team is small and product delivery is slipping behind connector maintenance, it may be smarter to hire full-stack developers for product-facing work and let a unified API absorb more of the integration churn.
The trade-off is straightforward. A unified layer can cut build time and reduce connector maintenance, but it also introduces dependency on the abstraction quality of that layer. If the provider's schema hides too much, developers end up adding source-specific exceptions anyway. If the schema is well designed, the application stays simpler without pretending every platform works the same way.
That is significant acceleration. Less duplicated integration code, fewer source-specific failure paths, and a shorter path from new platform request to working feature.
Making the Right Integration Choice for Your SaaS
The right decision comes down to engineering focus.
If your team has deep platform expertise, a long roadmap centered on connectivity, and enough capacity to own continual API maintenance, an in-house integration platform can be justified. You'll get tighter control, and you can shape the model around your exact use case.
Questions worth asking before you commit
A product manager or senior developer should pressure-test the decision with questions like these:
- What are your engineers not building while they're maintaining connectors?
- How many platforms must you support for the product to be viable in your market?
- How often do your target platforms change auth requirements, scopes, or payload formats?
- Can your support team diagnose source-specific failures once customers start connecting many stores?
- Do you need broad coverage now, or only a small set of high-priority integrations?
If those answers point toward a large and growing support matrix, third party aggregators start looking less like a shortcut and more like disciplined scope control.
When a unified layer makes more sense
A unified layer tends to fit when your product's value is in what you do with commerce data, not in the mechanics of collecting it.
That includes teams building reporting, automation, shipping workflows, inventory control, ERP sync, post-purchase operations, and multi-channel management. In those cases, the cleaner move is often to keep your engineers focused on business logic and use outside help for the connector surface. If you need to expand your team around that core product work, it can also help to review options for hire full-stack developers so integration work doesn't absorb all available engineering capacity.
The mistake is treating all integration work as equal. It isn't. Some parts create product advantage. Some parts are necessary but commoditized. Good teams know the difference and allocate effort accordingly.
If you're evaluating a unified integration layer for your SaaS, API2Cart is worth testing directly. A trial or demo is the fastest way to validate whether a single API can cover your required order, product, customer, shipment, and inventory workflows without forcing your team into another long connector build cycle.



