
You're probably dealing with the same pattern most integration developers hit sooner or later. The first store connector is manageable. The second exposes naming inconsistencies. By the fifth, every platform has its own payload shape, auth flow, pagination style, and webhook quirks, and your team is spending more time normalizing APIs than shipping product logic.
That's where a good OpenAPI specification example stops being “documentation work” and starts becoming architecture. If you build B2B SaaS for order management, shipping, inventory, ERP sync, or catalog operations, your API contract has to survive growth. It has to support generated docs, client SDKs, mocks, tests, governance, and onboarding for developers who didn't design the first version.
OpenAPI gives you a disciplined way to do that. Used well, it becomes the contract your backend, frontend, partner team, and support engineers all rely on. Used poorly, it turns into a stale file that nobody trusts. The difference usually comes down to precision, reuse, validation, and whether the spec accurately reflects the API your team ships.
Why a Solid API Specification Matters for eCommerce Integration
A B2B SaaS team usually feels the cost of a weak API contract during change, not during the first build. The first connector works. The second needs exceptions. By the time you support multiple commerce platforms, every new endpoint decision affects order sync, inventory updates, returns, customer records, and support workflows across the product.
That pressure shows up fast in custom eCommerce integration work. One merchant expects partial shipments to update at the line-item level. Another treats fulfillment as a separate resource with its own status model. A third sends the same business concept under different field names depending on the endpoint. Your internal API still needs to present stable behavior to the rest of the SaaS product.
Without a written contract, teams compensate with memory, code comments, and trial-and-error testing. That approach fails under scale. A connector gets patched for one merchant, another developer copies the pattern, and six months later nobody can say with confidence which response shape is intentional and which one is historical baggage.
OpenAPI fixes that by turning integration behavior into a contract your team can review, validate, version, and generate against. For eCommerce APIs, that matters because ambiguity spreads quickly. If status is loosely defined, every downstream workflow has to guess. If nullability is unclear, SDKs and mappings drift. If error responses are inconsistent, partner teams build retries around assumptions instead of guarantees. Teams that want clearer contract-first documentation can also use patterns from this guide to Swagger as an effective REST API documentation tool.
What breaks without a contract
In integration-heavy eCommerce products, the failure modes are usually familiar:
- Endpoint drift: shipped behavior changes, but docs and test fixtures stay behind.
- Schema ambiguity: fields like
price,inventory, andstatuscarry different meanings across services. - Connector sprawl: each platform adds custom mapping logic that is hard to reuse or test.
- Slow onboarding: new developers need to reverse-engineer business rules from controllers, logs, and merchant tickets.
- Support friction: support and QA teams cannot tell whether a bad payload is a client mistake or an undocumented API change.
Practical rule: If docs, mock payloads, and production responses disagree, maintenance cost goes up on every release.
This gets more expensive as your SaaS expands into new merchant segments. Different store stacks often imply different order models, catalog rules, and authentication constraints. If you are validating that expansion strategy, this B2B e-commerce platform comparison is useful context before you commit engineering time to more custom connectors.
What a strong spec changes
A strong OpenAPI contract gives engineering, QA, support, and partners the same source of truth. It forces precise decisions early. Is an order ID immutable? Can discount_total be omitted or only set to null? Does a failed authorization return one standard error object or several variants depending on the endpoint? Those choices matter more in B2B SaaS than in a one-off internal app because every inconsistency turns into migration work, SDK issues, or broken partner flows.
It also creates a practical path to scale. Teams can lint the spec in CI, generate clients, produce mocks for frontend or partner testing, and review contract changes before they hit production. That discipline is what keeps a growing integration surface maintainable.
For teams building many custom commerce integrations, OpenAPI also exposes a business trade-off. You can keep defining and maintaining platform-by-platform contracts yourself, or reduce that surface area with a unified API layer such as API2Cart and spend more time on product logic than connector normalization.
Understanding the Core OpenAPI Structure
A team ships its first connector quickly. Six months later, that same team is supporting product sync, order import, shipment updates, and customer lookups across several commerce platforms. At that point, the OpenAPI file stops being "documentation" and starts acting like an operating contract for the integration.
That matters even more in B2B SaaS. Different merchants expect different fields, auth flows, and error handling, but your product still needs one predictable integration surface. A clear OpenAPI structure is how teams keep that complexity under control, whether they maintain each connector themselves or reduce that work with a unified API layer such as API2Cart.
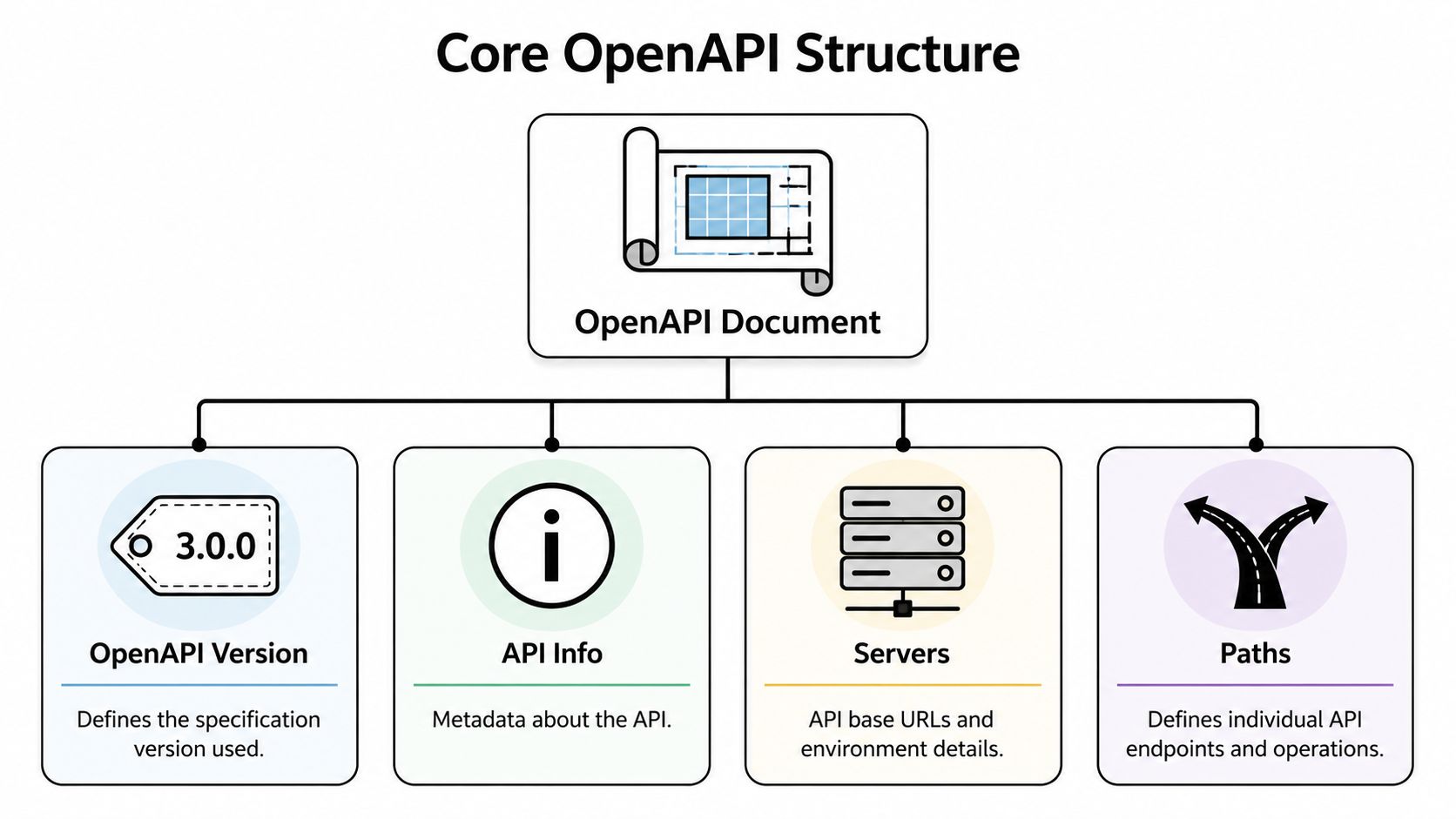
The top-level pieces that matter
These are the sections integration developers usually check first:
| Section | What it does | Why it matters |
|---|---|---|
openapi |
Declares the spec version | Tooling behavior depends on it |
info |
Holds metadata like title and version | Helps consumers identify the API and release |
servers |
Lists base URLs | Keeps dev, staging, and production explicit |
paths |
Defines endpoints and operations | Describes request and response behavior |
components |
Stores reusable schemas and security definitions | Reduces duplication and keeps large specs maintainable |
If you work across multiple request patterns, it also helps to understand API types for SaaS before you model resources. That context helps when you need to decide whether an operation belongs in a collection path, a single-resource path, or a callback flow.
A minimal hello world in YAML
YAML is usually easier to review in pull requests and faster to edit by hand. That is why many integration teams write the source spec in YAML even if downstream tooling converts it.
openapi: 3.0.0
info:
title: Hello API
version: 1.0.0
servers:
- url: https://api.example.com
paths:
/hello:
get:
summary: Returns a greeting
responses:
'200':
description: Successful response
The same file in JSON
JSON expresses the same contract. Some generators and internal pipelines prefer it, especially when specs are produced programmatically.
{
"openapi": "3.0.0",
"info": {
"title": "Hello API",
"version": "1.0.0"
},
"servers": [
{
"url": "https://api.example.com"
}
],
"paths": {
"/hello": {
"get": {
"summary": "Returns a greeting",
"responses": {
"200": {
"description": "Successful response"
}
}
}
}
}
}
How to read it like an integration developer
Read the file in the same order your implementation risks appear.
- Which spec version is this using
- What API am I looking at
- Which environment URLs are defined
- Which paths and methods exist
- What request, response, and security rules apply
For eCommerce work, I usually inspect paths and components together. A path tells you what the endpoint does. The shared schemas tell you whether the team is modeling orders, products, and customers consistently across the whole API. That consistency is what keeps SDK generation, contract testing, and partner onboarding from turning into cleanup work later.
Machine-readable structure is a key advantage here. Once the contract is precise, teams can generate docs, validate examples, lint changes in CI, and catch drift before it reaches merchants or partners. For a practical reference on documenting those contracts well, this guide to effective REST API documentation with Swagger is useful.
Example 1 A Minimal Single-Endpoint API
Start with one endpoint that every commerce system understands. Product lookup is a good candidate because it forces you to model identifiers, path parameters, a success payload, and an error response without burying the example in too much complexity.
Here's a compact OpenAPI specification example for GET /products/{productId}:
openapi: 3.0.0
info:
title: Product API
version: 1.0.0
paths:
/products/{productId}:
get:
summary: Get a product by ID
parameters:
- name: productId
in: path
required: true
description: Unique product identifier
schema:
type: string
responses:
'200':
description: Product found
content:
application/json:
schema:
type: object
required:
- id
- name
- price
properties:
id:
type: string
name:
type: string
price:
type: number
format: float
'404':
description: Product not found
What each part is doing
The paths entry names the route exactly as the API exposes it. Inside that, get defines the HTTP operation. The summary is short on purpose. It gives generated docs a useful label without trying to explain the whole business process.
The parameters array documents productId as a path parameter. Because it sits in the URL path, required: true isn't optional. If you skip that detail, generated clients and docs often become less reliable.
The 200 response defines the successful payload. Even in a small example, the schema should include required properties so consumers know which fields they can depend on. For commerce integrations, that distinction matters. A downstream sync process might tolerate a missing optional description, but it probably can't operate without id, name, or price.
What makes this example useful
A lot of beginner examples stop at “returns product data.” That's not enough for real integration work. You need enough detail to answer these questions:
- What type is the identifier
- Which fields are guaranteed
- What does failure look like
- Can client code validate the response shape
Good API specs remove negotiation. Consumers shouldn't have to ask whether
priceis a string in one store and a number in another.
A few practical improvements
Before you use this pattern in production, tighten it:
- Add
operationId: This gives generated clients a stable method name. - Document examples: Sample payloads make docs easier to understand.
- Define an error schema: A plain
404description is readable, but a structured error body is more useful. - Reuse schemas later: Once you add more product endpoints, move the product shape into
components.
That's the moment a minimal endpoint starts turning into an actual contract rather than a code comment with indentation.
Example 2 A Full CRUD Collection Endpoint
A catalog integration usually breaks down after the first successful GET. Reading one product is easy. Keeping list, create, update, and delete behavior consistent across dozens of merchant connectors is where the specification starts doing real work.

For a B2B SaaS team, this matters early. The moment you sync catalog data between an app and several commerce platforms, every mismatch in field names, request bodies, and response shapes turns into connector-specific code. A well-structured OpenAPI document reduces that drift because the shared model lives in one contract, not in scattered handler logic and tribal knowledge.
A reusable Product schema
Once multiple operations use the same product shape, define it once under components and reference it everywhere.
openapi: 3.0.0
info:
title: Catalog API
version: 1.0.0
paths:
/products:
get:
summary: List products
responses:
'200':
description: Product list
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/Product'
post:
summary: Create a product
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/ProductInput'
responses:
'201':
description: Product created
content:
application/json:
schema:
$ref: '#/components/schemas/Product'
/products/{productId}:
put:
summary: Update a product
parameters:
- name: productId
in: path
required: true
schema:
type: string
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/ProductInput'
responses:
'200':
description: Product updated
content:
application/json:
schema:
$ref: '#/components/schemas/Product'
delete:
summary: Delete a product
parameters:
- name: productId
in: path
required: true
schema:
type: string
responses:
'204':
description: Product deleted
components:
schemas:
Product:
type: object
required:
- id
- name
- sku
- price
properties:
id:
type: string
name:
type: string
sku:
type: string
price:
type: number
format: float
ProductInput:
type: object
required:
- name
- sku
- price
properties:
name:
type: string
sku:
type: string
price:
type: number
format: float
Why this version holds up in production
The benefit is operational, not cosmetic. Product and ProductInput give every CRUD operation the same baseline contract, so adding currency, status, localized fields, or validation rules happens in one place. Generated SDKs stay aligned. Tests become simpler to maintain. Reviewers can spot breaking changes before they hit a merchant account.
That pattern is especially useful in B2B SaaS. Product models rarely stay flat for long. Teams end up adding channel mappings, warehouse quantities, tax classes, bundle relationships, and custom attributes required by one marketplace but not another. A centralized schema does not remove that complexity, but it keeps it from spreading through every endpoint.
There is also a practical boundary here. If your product contract starts absorbing platform-specific quirks from every store, the OpenAPI file becomes hard to reason about. That is one reason unified integration layers exist. Services such as API2Cart give teams a normalized commerce model so they spend less time reconciling authentication, catalog structure, and platform differences. Their guide to API authentication patterns for integrations is a useful reference when these CRUD endpoints later need access control.
CRUD design choices worth making early
A few decisions save a lot of cleanup later:
- Separate input from output:
ProductInputomits server-managed fields likeid, which keeps clients from sending values they do not own. - Define collection and single-resource behavior consistently: If
skuis the canonical field in one operation, keep it canonical everywhere. - Use
204for delete when nothing is returned: Clients should not guess whether a delete response includes a body. - Plan for partial updates intentionally: If your API will support PATCH later, document that separately instead of overloading PUT semantics.
- Standardize error payloads across CRUD actions: Validation failures, missing records, and conflict cases should not each invent their own shape.
Field note: Integration issues usually come from small inconsistencies between similar endpoints. A spec that keeps CRUD behavior predictable cuts custom mapping code and shortens onboarding for every new connector.
Example 3 Authentication and Protected Endpoints
Commerce APIs carry customer details, order history, addresses, and pricing data. If the spec doesn't document security clearly, the integration fails before business logic even starts. Most of the wasted time in protected endpoints comes from guessing where credentials go, which operations require them, and what error response means “bad key” versus “insufficient permission.”

Defining an API key scheme
A simple API key in a request header is common for internal admin APIs, partner APIs, and gateway-style integrations.
openapi: 3.0.0
info:
title: Secure Order API
version: 1.0.0
components:
securitySchemes:
ApiKeyAuth:
type: apiKey
in: header
name: X-API-Key
paths:
/orders:
get:
summary: List orders
security:
- ApiKeyAuth: []
responses:
'200':
description: Order list
'401':
description: Missing or invalid API key
'403':
description: Authenticated but not allowed
The securitySchemes object defines how authentication works. The operation-level security block applies that scheme to GET /orders. If most endpoints share the same auth requirement, you can move security to the top level and override it only where needed.
Documenting 401 and 403 correctly
This distinction saves debugging time.
| Status | Meaning | Common cause |
|---|---|---|
401 |
The request wasn't successfully authenticated | Missing key, invalid key, malformed credentials |
403 |
The caller is authenticated but not authorized | Key is valid, but permissions are too limited |
Many APIs blur these responses. Your spec shouldn't. A consumer needs to know whether to rotate credentials, request broader access, or fix a header format bug.
What secure specs include beyond the happy path
When you document protected endpoints, don't stop at the auth scheme:
- State where the credential is sent: header, query, or cookie.
- Apply security deliberately: global if nearly everything is protected, operation-level if only some routes are.
- Return structured errors: consumers need machine-readable error bodies, not only descriptions.
- Document permission-sensitive operations: deleting orders, changing inventory, or updating customer records may need stronger scopes or roles.
If you want a broader technical refresher on auth models and implementation concerns, this overview of authentication in API design is a practical reference.
Security documentation isn't extra polish. It's part of the runtime contract.
Advanced Examples Pagination Filters and Webhooks
A spec looks fine in staging with ten products and one test order. The weak points show up after onboarding real merchants. A 200,000-SKU catalog stresses pagination, incremental sync depends on clear filters, and order events need a defined webhook contract if your B2B SaaS is feeding ERP, WMS, or fulfillment logic.
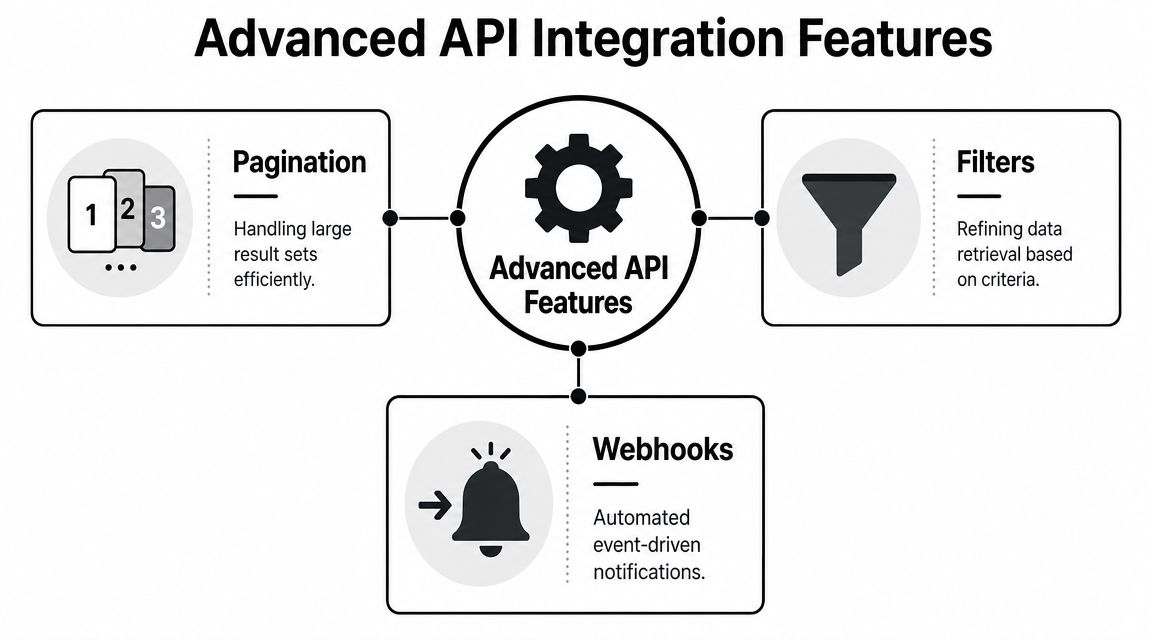
For eCommerce integrations, this part of the spec often decides whether the connector stays maintainable six months later. Good OpenAPI documents do more than list fields. They define how clients page safely, which filters support efficient sync, and how asynchronous events arrive. Teams building products such as order management, inventory sync, or merchant analytics need that contract early, especially if they plan to support many cart platforms later or eventually consolidate connector logic behind a unified layer like API2Cart.
Pagination and filtering for product sync
A product collection endpoint usually needs bounded result sets and filters designed for sync jobs, not just UI browsing.
paths:
/products:
get:
summary: List products
parameters:
- name: limit
in: query
schema:
type: integer
minimum: 1
- name: offset
in: query
schema:
type: integer
minimum: 0
- name: status
in: query
schema:
type: string
enum: [active, archived]
- name: updated_after
in: query
schema:
type: string
format: date-time
responses:
'200':
description: Product page
This definition affects real integration behavior. If updated_after is documented and stable, a sync worker can pull only changed records. If it is vague, teams fall back to full recrawls, custom diffing, and rate-limit problems.
Offset pagination is easy to understand, but it can drift on fast-changing datasets. Cursor pagination is often safer for orders, transactions, and inventory updates because inserts between requests do not reshuffle the page boundary as easily. If you are weighing those trade-offs, this guide to pagination in API design covers the implementation choices that matter in production.
Filters need the same discipline. Document allowed operators, value formats, and timezone assumptions. updated_after without a clear date-time format turns into support tickets. Enum filters such as status should use controlled values because integration code often maps them directly into internal job states.
That matters even more for SaaS teams working with merchants on platform-specific stack decisions, including building a winning Shopify tech stack. The more variation exists upstream, the more your own API contract needs to remove ambiguity.
Webhooks for event-driven flows
Polling still works for some jobs. It is expensive and slow for others.
Order ingestion is the obvious case. If a merchant creates an order and your system should reserve stock, create an invoice, or queue shipment logic, the event payload deserves the same level of specification as any REST response.
webhooks:
orderCreated:
post:
requestBody:
required: true
content:
application/json:
schema:
type: object
required:
- event
- orderId
properties:
event:
type: string
enum: [order.created]
orderId:
type: string
createdAt:
type: string
format: date-time
responses:
'200':
description: Webhook received
A useful webhook definition includes more than the payload shape. Document retry behavior, expected acknowledgment status, signature verification, idempotency expectations, and whether events can arrive out of order. Commerce systems do produce duplicates and race conditions. The spec should prepare consumers for that instead of leaving them to infer behavior from logs.
OpenAPI support for webhooks helps keep those async contracts in the same source of truth as the rest of the API. That reduces the common problem where webhook docs drift into a separate page and stop matching what the sender posts.
Modeling richer payloads with enum and oneOf
Commerce data is full of cases where one business concept has multiple valid shapes. Payment details are a common example.
components:
schemas:
PaymentMethod:
oneOf:
- $ref: '#/components/schemas/CardPayment'
- $ref: '#/components/schemas/BankTransferPayment'
CardPayment:
type: object
required: [type, last4]
properties:
type:
type: string
enum: [card]
last4:
type: string
BankTransferPayment:
type: object
required: [type, accountReference]
properties:
type:
type: string
enum: [bank_transfer]
accountReference:
type: string
This pattern pays off when downstream systems branch on payment type. A typed union is easier to validate, mock, and generate SDKs from than a loose object with optional fields for every possible method. Add examples, required fields, and validation constraints directly in the schema so generated docs and test fixtures stay aligned.
Where maintainability usually breaks
The hard part is not writing one good example. It is keeping examples, schemas, and runtime behavior consistent as the integration surface grows.
Teams usually avoid drift by doing four things:
- Validate examples against schemas in CI
- Centralize reusable collection and event schemas
- Keep enum values stable and version changes explicitly
- Design filters and webhook events around sync workflows, not only human-readable docs
That is the difference between an OpenAPI specification example that looks polished and one that supports a scalable eCommerce integration program.
How to Accelerate eCommerce Integration with API2Cart
There's a point where writing a careful spec for your own API is only half the battle. The other half is upstream complexity. If your SaaS integrates with many shopping carts and marketplaces, you still have to account for different external payloads, auth patterns, order models, inventory semantics, and change cycles.
That's where a unified abstraction can change the delivery model. Instead of building and maintaining a separate connector for every commerce platform, a team can integrate once against a normalized API surface and spend more effort on mapping business workflows than on connector plumbing. For a B2B SaaS team, that often matters most in order import, inventory sync, catalog updates, shipment pushes, and customer data retrieval.
Where the unified approach fits
One practical option is API2Cart, which provides a unified eCommerce API for connecting B2B software to many shopping carts and marketplaces through one integration layer. For an OMS, that means a single order retrieval flow can feed imports from different merchant platforms without requiring your team to handcraft every connector. For a PIM or inventory platform, it means pushing catalog and stock updates through one contract instead of maintaining separate logic branches for each cart family.
That doesn't remove the need for good API design inside your own product. You still need strong internal schemas, clear errors, versioning rules, and sync behavior. What it can remove is a large part of the repetitive upstream connector work.
Use cases integration developers care about
A unified layer is especially useful when your backlog includes work like this:
- Order ingestion: pull orders from many merchant stores into one downstream pipeline.
- Inventory synchronization: update stock levels across connected stores from one internal inventory event.
- Catalog operations: read and write product data without learning each store's native shape.
- Operational reporting: aggregate store, customer, and order data into one analytics model.
If you're working with merchants on storefront strategy as well as backend connectivity, content like this guide to building a winning Shopify tech stack can help connect integration requirements with the broader app ecosystem decisions those merchants make.
The trade-off to keep in mind
The trade-off is abstraction versus direct control. A unified API can simplify onboarding and maintenance, but your team still needs to understand where platform-specific behavior leaks through. Returns, discounts, fulfillment state, and custom fields are the kinds of edges where normalized APIs need careful handling.
The right question isn't “Should we use OpenAPI or a unified API.” It's “Where should our engineers spend their time.” If your product differentiates on workflow automation, analytics, orchestration, or business rules, spending less time on one-off connector maintenance is often the better engineering bet.
Best Practices Versioning Validation and Tooling
A spec starts losing value the moment it stops matching production. In eCommerce integrations, that usually shows up as one team shipping a new order status, another team updating docs later, and customer-facing integrations breaking in the gap. For a B2B SaaS product, that gap turns into support tickets, brittle client code, and slower partner onboarding.
Good OpenAPI maintenance is mostly an engineering discipline problem. Syntax is the easy part. The harder part is preventing schema drift across services, examples, SDKs, and docs as your API grows and multiple teams touch it.
Versioning choices
Pick a versioning model your support team and client developers can work with under pressure.
- Path-based versioning makes the contract explicit.
/v2/productsis easy to route, test, log, and discuss in bug reports. - Header-based versioning keeps resource URLs cleaner, but it adds friction during debugging because the active version is not obvious from the request path alone.
- Deprecation policy matters as much as the version format. Define how long old versions stay available, what counts as a breaking change, and how clients will be notified.
For many integration teams, path-based versioning is the safer default. It is less elegant on paper, but easier to operate in real environments where QA, support, and partner engineers all need to see what changed quickly.
Validation and governance habits
Treat the spec like source code. Every change should be reviewed, validated, and traced to implementation work.
- Validate on every pull request: catch broken references, invalid examples, and missing required fields before merge.
- Keep examples close to schemas: this reduces drift, especially in larger repos with many contributors.
- Enforce naming consistency: if a field is
productId, keep itproductIdacross endpoints and events. - Split large specs with clear ownership: multi-file OpenAPI works well only when teams know which parts they own and review.
If the spec changes, generated docs, contract tests, and implementation checks should change with it.
That rule matters even more in B2B SaaS. Once external customers build against your contract, small inconsistencies become long-lived integration costs.
Tooling that actually helps
Tooling is useful when it reduces repeat work and exposes contract problems early. Use the spec to generate docs, mock responses, test fixtures, SDKs, or server scaffolding where those outputs fit your workflow. Skip blind code generation if your team will spend more time cleaning generated artifacts than maintaining a small hand-written layer.
For custom eCommerce integrations, the practical goal is simple. Keep OpenAPI as the source of truth for your internal contract, validate it in CI, and make sure every production change is reflected there first or at the same time.
If your team is building B2B eCommerce software across many platforms, a unified API approach can reduce how much connector-specific behavior your spec has to describe and maintain. API2Cart is one option to evaluate for that model. It gives integration teams a single interface to many commerce platforms, which can shorten the path from API design to a working multi-platform integration while still letting your team keep a clean OpenAPI contract around its own product surface.



